运算|用什么tricks能让模型训练得更快?先了解下这个问题的第一性原理
选自horace博客
作者:Horace He
机器之心编译
编辑:Juniper
深度学习是门玄学?也不完全是 。每个人都想让模型训练得更快 , 但是你真的找对方法了吗?在康奈尔大学本科生、曾在 PyTorch 团队实习的 Horace He 看来 , 这个问题应该分几步解决:首先 , 你要知道为什么你的训练会慢 , 也就是说瓶颈在哪儿 , 其次才是寻找对应的解决办法 。 在没有了解基本原理(第一性原理)之前就胡乱尝试是一种浪费时间的行为 。
在这篇文章中 , Horace He 从三个角度分析可能存在的瓶颈:计算、内存带宽和额外开销 , 并提供了一些方式去判断当前处于哪一个瓶颈 , 有助于我们更加有针对性地加速系统 。 这篇文章得到了陈天奇等多位资深研究者、开发者的赞赏 。
文章图片
以下是原文内容:
怎样才能提高深度学习模型的性能?一般人都会选择网上博客中总结的一些随机技巧 , 比如「使用系统内置的运算算子 , 把梯度设置为 0 , 使用 PyTorch1.10.0 版本而不是 1.10.1 版本……」
在这一领域 , 当代(特别是深度学习)系统给人的感觉不像是科学 , 反而更像炼丹 , 因此不难理解用户为什么倾向于采用这种随机的方法 。 即便如此 , 这一领域也有些第一性原理可以遵循 , 我们可以据此排除大量方法 , 从而使得问题更加容易解决 。
比如 , 如果你的训练损失远低于测试损失 , 那么你可能遇到了「过拟合」问题 , 而尝试着增加模型容量就是在浪费时间 。 再比如 , 如果你的训练损失和你的验证损失是一致的 , 那对模型正则化就显得不明智了 。
类似地 , 你也可以把高效深度学习的问题划分为以下三个不同的组成部分:
- 计算:GPU 计算实际浮点运算(FLOPS)所花费的时间;
- 内存:在 GPU 内传输张量所花费的时间;
- 额外开销:花在其它部分的时间 。
所以 , 如果你想让 GPU 丝滑运行 , 以上三个方面的讨论和研究就是必不可少的 。

文章图片
惨痛教训的背后有大量工程师保持 GPU 高效运行 。
注意:这个博客中的大多数内容是基于 GPU 和 PyTorch 举例子的 , 但这些原则基本是跨硬件和跨框架通用的 。
计算
优化深度学习系统的一个方面在于我们想要最大化用于计算的时间 。 你花钱买了 312 万亿次浮点数运算 , 那你肯定希望这些都能用到计算上 。 但是 , 为了让你的钱从你昂贵的矩阵乘法中得到回报 , 你需要减少花费在其他部分的时间 。
但为什么这里的重点是最大化计算 , 而不是最大化内存的带宽?原因很简单 —— 你可以减少额外开销或者内存消耗 , 但如果不去改变真正的运算 , 你几乎无法减少计算量 。
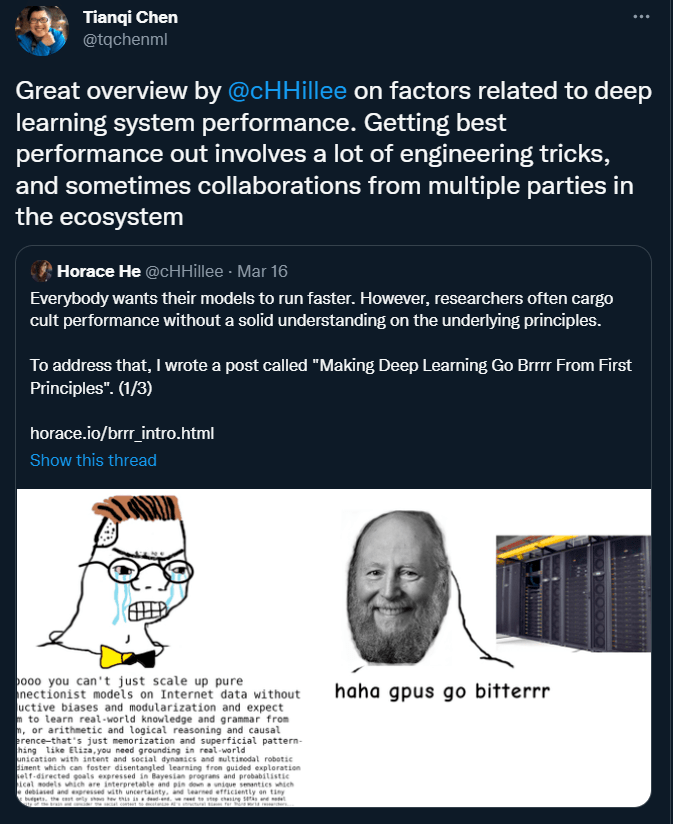
与内存带宽相比 , 计算的增长速度增加了最大化计算利用率的难度 。 下表显示了 CPU 的 FLOPS 翻倍和内存带宽翻倍的时间 (重点关注黄色一栏) 。
文章图片
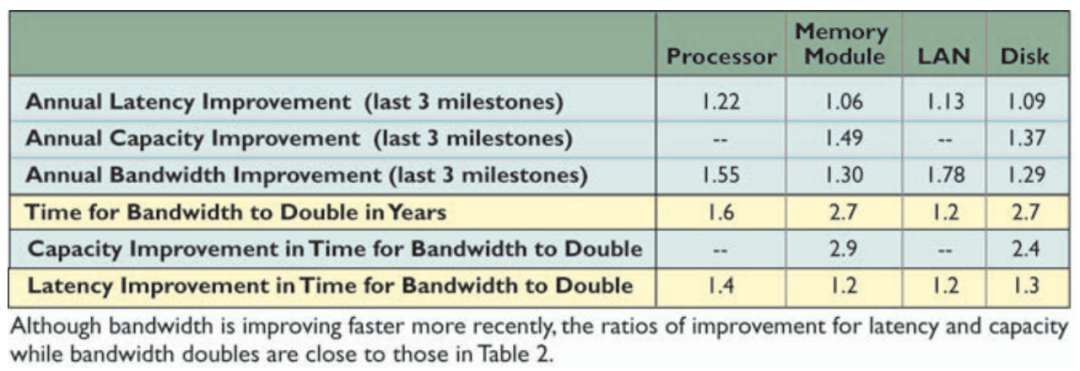
一种理解计算的方式是把它想象成工厂 。 我们把指令传达给我们的工厂(额外消耗) , 把原始材料送给它(内存带宽) , 所有这些都是为了让工厂运行得更加高效(计算) 。
文章图片
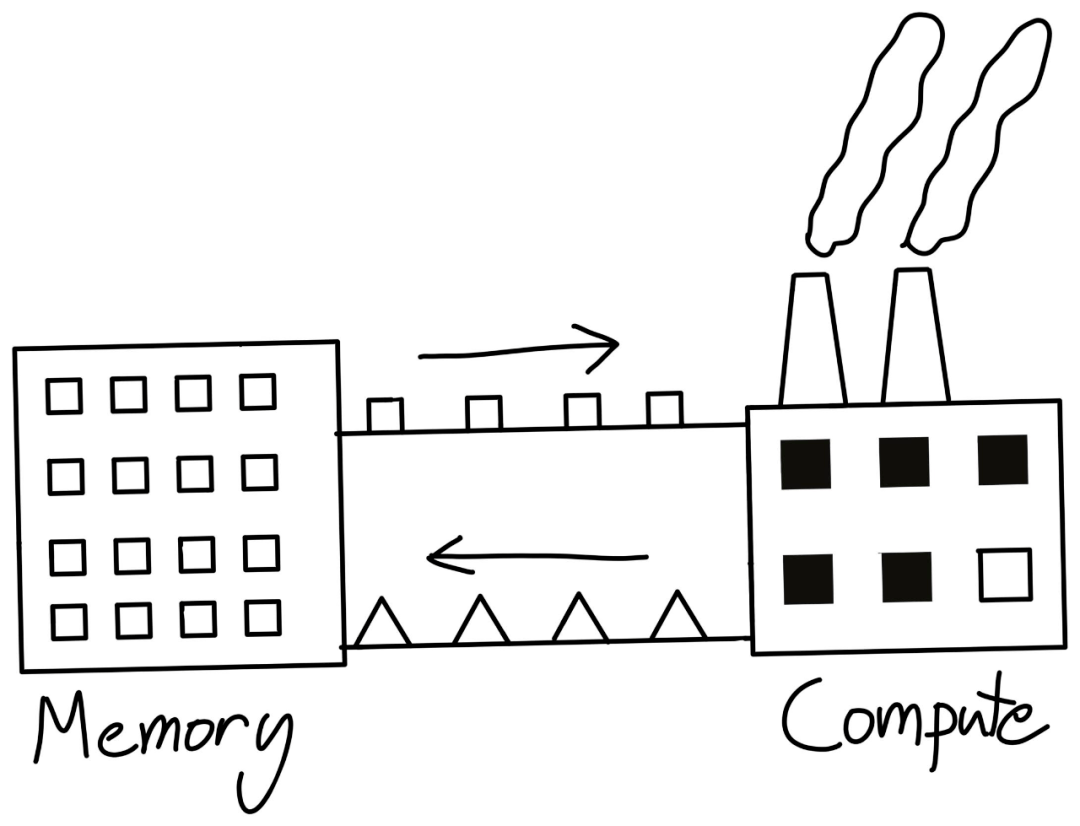
所以 , 如果工厂容量扩展的速度高于我们提供给它原材料的速度 , 它就很难达到一个顶峰效率 。
文章图片
即使我们工厂容量(FLOP)翻倍 , 但带宽跟不上 , 我们的性能也不能翻倍 。
关于 FLOPS 还有一点要说 , 越来越多的机器学习加速器都有专门针对矩阵乘法的硬件配置 , 例如英伟达的「Tensor Cores」 。

文章图片
所以 , 你要是不做矩阵乘法的话 , 你只能达到 19.5 万亿次运算 , 而不是 312 万亿次 。 注意 , 并不是只有 GPU 这么特殊 , 事实上 TPU 是比 GPU 更加专门化的计算模块 。
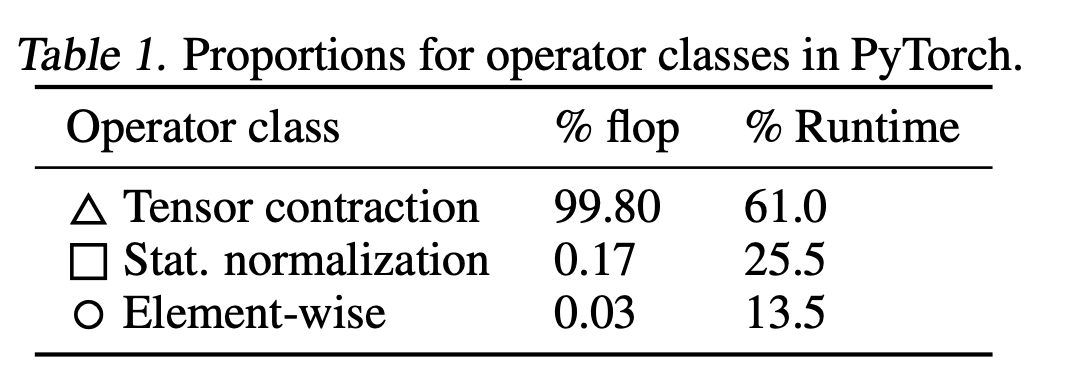
除了矩阵乘法以外 , GPU 处理其他运算时都比较慢 , 这一现象乍看上去似乎有问题:比如像是层归一化或者激活函数的其它算子怎么办呢?事实上 , 这些算子在 FLOPS 上仅仅像是矩阵乘法的舍入误差一样 。 例如 , 看看下表对于 BERT 中的不同算子类型占用的 FLOP 数 , 其中的「Tensor Contraction」就是指矩阵乘法 。
文章图片
可以看到 , 非矩阵乘法运算仅仅占所有运算的 0.2% , 所以即使它们的速度仅为矩阵乘法的 1/15 也没什么问题 。
事实上 , 归一化运算和逐点(pointwise)运算使用的 FLOPS 仅为矩阵乘法的 1/250 和 1/700 。 那为什么非矩阵乘法运算会远比它们应该使用的运行时间更多呢?
回到前文「工厂」的类比 , 罪魁祸首经常还是如何将原始材料运到以及运出工厂 , 换句话说 , 也就是「内存带宽」 。
带宽
带宽消耗本质上是把数据从一个地方运送到另一个地方的花费 , 这可能是指把数据从 CPU 移动到 GPU , 从一个节点移动到另一个节点 , 甚至从 CUDA 的全局内存移动到 CUDA 的共享内存 。 最后一个是本文讨论的重点 , 我们一般称其为「带宽消耗」或者「内存带宽消耗」 。 前两者一般叫「数据运输消耗」或者「网络消耗」 , 不在本文叙述范围之内 。
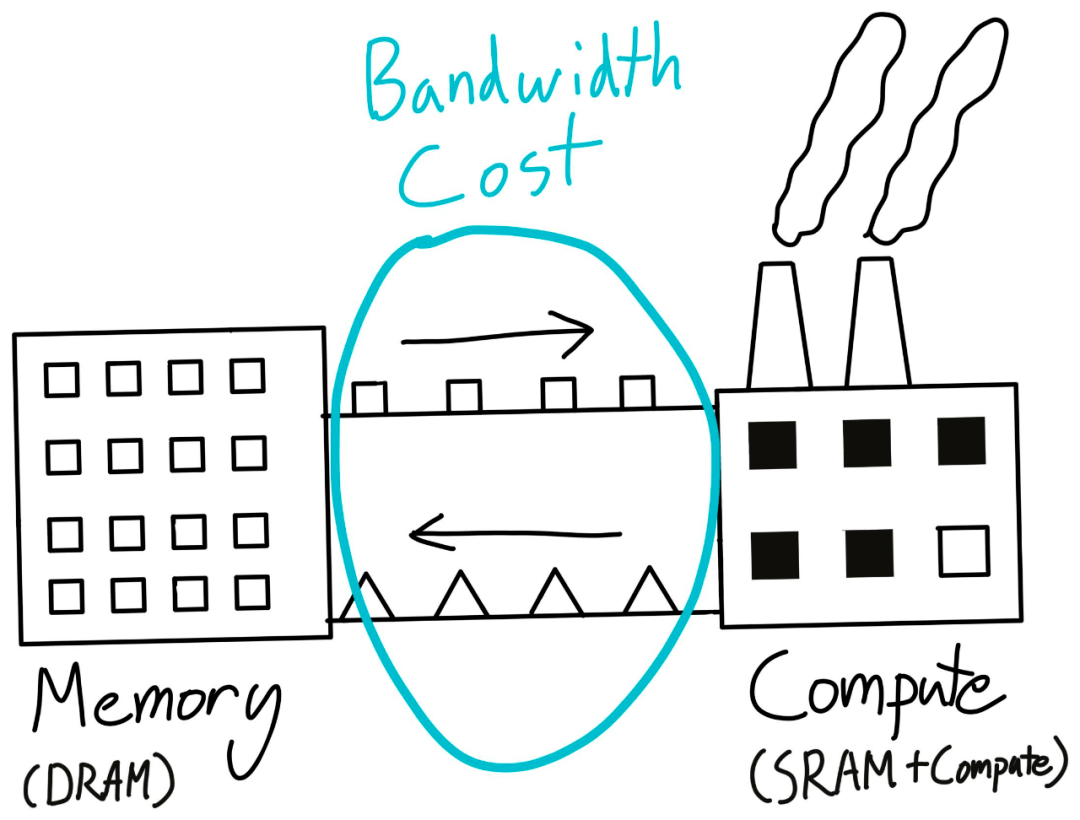
还是回到「工厂」的类比 。 虽然我们在工厂中从事实际的工作 , 但它并不适合大规模的存储 。 我们要保证它的存储是足够高效的 , 并且能够很快去使用(SRAM) , 而不是以量取胜 。
那么我们在哪里存储实际的结果和「原材料」呢?一般我们要有一个仓库 , 那儿的地足够便宜 , 并且有大量的空间(DRAM) 。 之后我们就可以在它和工厂之间运送东西了(内存带宽) 。
文章图片
这种在计算单元之间移动东西的成本就是所谓的「内存带宽」成本 。 事实上 , nvidia-smi 命令中出现的那个「内存」就是 DRAM , 而经常让人抓狂的「CUDA out of memory」说的就是这个 DRAM 。
值得注意的是:我们每执行一次 GPU 核运算都需要把数据运出和运回到我们的仓库 ——DRAM 。
现在想象一下 , 当我们执行一个一元运算(如 torch.cos)的时候 , 我们需要把数据从仓库(DRAM)运送到工厂(SRAM) , 然后在工厂中执行一小步计算 , 之后再把结果运送回仓库 。 运输是相当耗时的 , 这种情况下 , 我们几乎把所有的时间都花在了运输数据 , 而不是真正的计算上 。
因为我们正把所有的时间都花费在内存带宽上 , 这种运算也被称作内存限制运算(memory-bound operation) , 它意味着我们没有把大量时间花费在计算上 。
显然 , 这并不是我们想要的 。 那我们能做什么呢?让我们来看看算子序列长什么样子 。
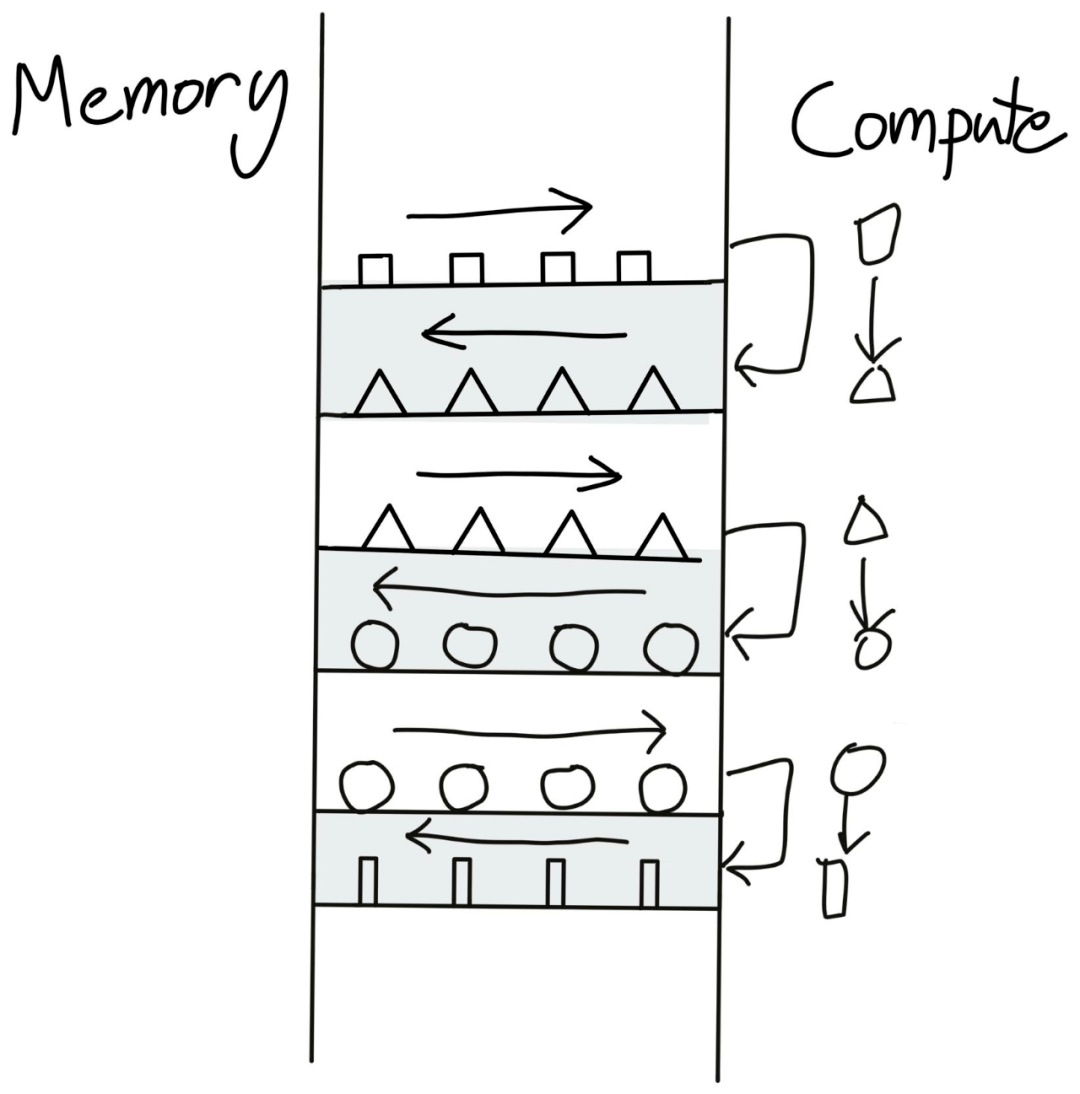
文章图片
一个逐点算子序列可能的样子 。
在全局内存和计算单元之间来回传输数据的做法显然不是最佳的 。 一种更优的方式是:在数据工厂中一次性执行完全部运算再把数据传回 。
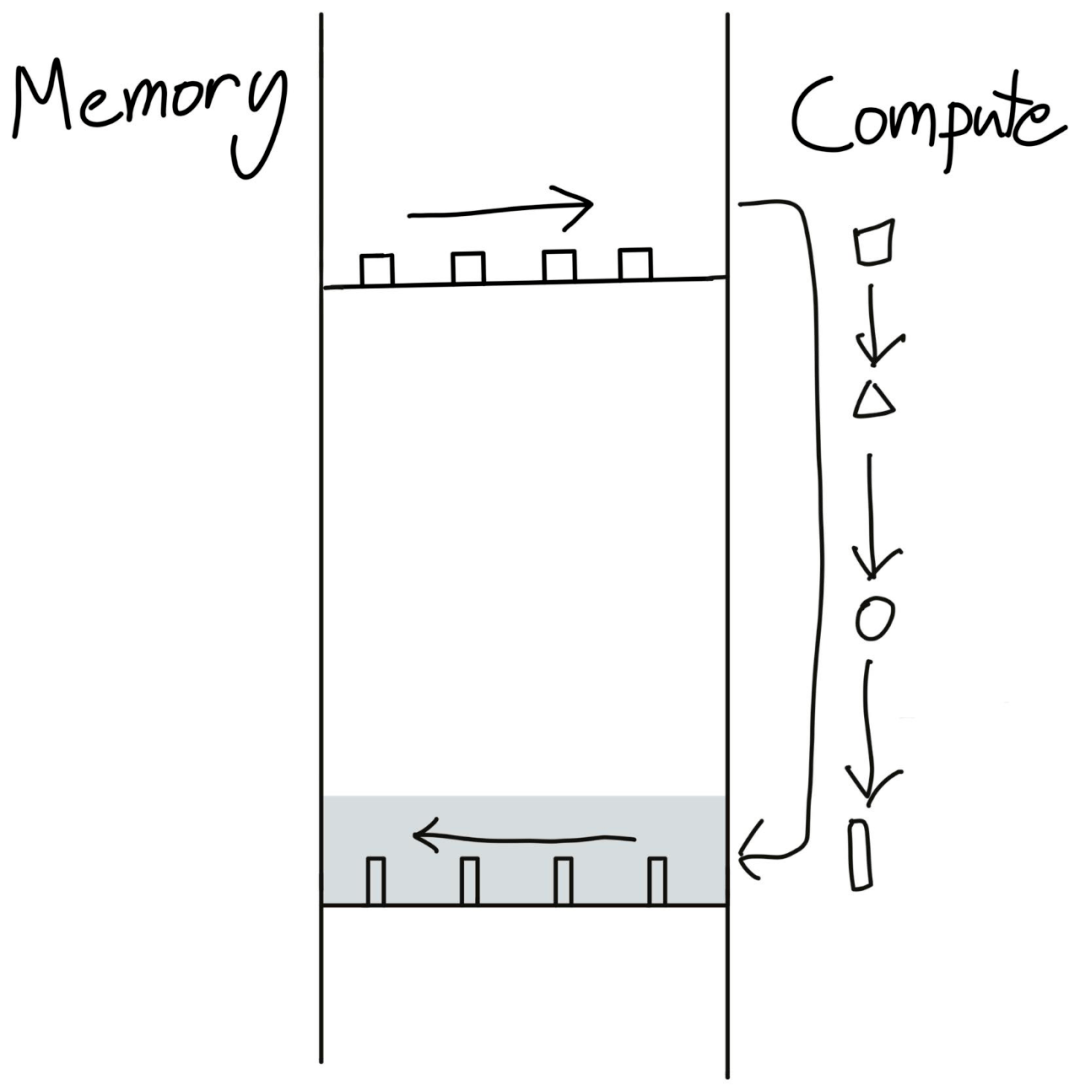
文章图片
这就是算子融合(operator fusion)—— 深度学习编译器中最重要的优化 。 简单地说 , 这种方法不会为了再次读取而将数据写入全局内存 , 而是通过一次执行多个计算来避免额外的内存访问 。
例如 , 执行 x.cos ().cos () 运算 , 写入内存的方式需要 4 次全局读写 。
x1 = x.cos() # Read from x in global memory, write to x1
x2 = x1.cos() # Read from x1 in global memory, write to x2
而算子融合只需要 2 次全局内存读写 , 这样就实现了 2 倍加速 。
x2 = x.cos().cos() # Read from x in global memory, write to x2
但是这种做法也并不容易 , 需要一些条件 。 首先 , GPU 需要知道执行完当前运算后下一步会发生什么 , 因此无法在 PyTorch 的 Eager 模式(一次运行一个运算符)下进行此优化 。 其次 , 我们需要编写 CUDA 代码 , 这也不是一件简单的事 。
并不是所有的算子融合都像逐点算子那样简单 。 你可以将逐点算子融合到归约(reduction)或矩阵乘法上 。 甚至矩阵乘法本身也可以被认为是一种融合了广播乘法(broadcasting multiply)和归约的运算 。
任何 2 个 PyTorch 算子都可以被融合 , 从而节省了读取 / 写入全局内存的内存带宽成本 。 此外 , 许多现有编译器通常可以执行「简单」的融合(例如 NVFuser 和 XLA) 。 然而 , 更复杂的融合仍然需要人们手动编写 , 因此如果你想尝试自己编写自定义 CUDA 内核 , Triton 是一个很好的起点 。
令人惊讶的是 , 融合后的 x.cos ().cos () 运算将花费几乎与单独调用 x.cos () 相同的时间 。 这就是为什么激活函数的成本几乎是一样的 , 尽管 gelu 显然比 relu 包含更多的运算 。
因此 , 重新实现 / 激活检查点会产生一些有趣的结果 。 从本质上讲 , 进行额外的重新计算可能会导致更少的内存带宽 , 从而减少运行时间 。 因此 , 我们可以通过重新实现来减少内存占用和运行时间 , 并在 AOTAutograd 中构建一个简洁的 min-cut 优化通道 。
推理内存带宽成本
对于简单的运算 , 直接推理内存带宽是可行的 。 例如 , A100 具有 1.5 TB / 秒的全局内存带宽 , 可以执行 19.5 teraflops / 秒的计算 。 因此 , 如果使用 32 位浮点数(即 4 字节) , 你可以在 GPU 执行 20 万亿次运算的同时加载 4000 亿个数字 。
此外 , 执行简单的一元运算(例如将张量 x2)实际上需要将张量写回全局内存 。
因此直到执行大约一百个一元运算之前 , 更多的时间是花在了内存访问而不是实际计算上 。
如果你执行下面这个 PyTorch 函数:
def f(x: Tensor[N]):
for _ in range(repeat):
x = x * 2
【运算|用什么tricks能让模型训练得更快?先了解下这个问题的第一性原理】return x
并使用融合编译器对其进行基准测试 , 就可以计算每个 repeat 值的 FLOPS 和内存带宽 。 增大 repeat 值是在不增加内存访问的情况下增加计算量的简单方法 - 这也称为增加计算强度 (compute intensity) 。
具体来说 , 假设我们对这段代码进行基准测试 , 首先要找出每秒执行的迭代次数;然后执行 2N(N 是张量大小)次内存访问和 N *repeat FLOP 。 因此 , 内存带宽将是 bytes_per_elem * 2 * N /itrs_per_second , 而 FLOPS 是 N * repeat /itrs_per_second 。
现在 , 让我们绘制计算强度的 3 个函数图象:运行时间、flops 和内存带宽 。
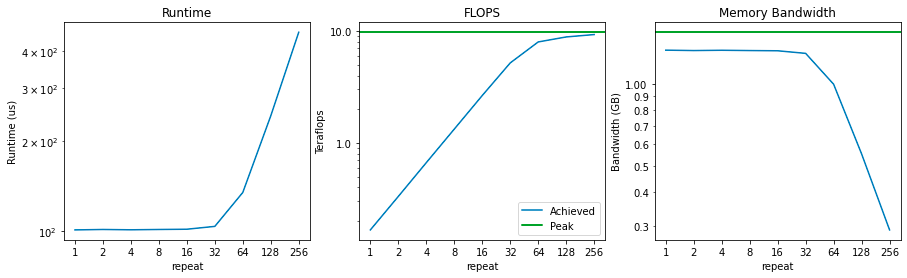
文章图片
请注意 , 在执行 64 次乘法之前 , 运行时间根本不会显著增加 。 这意味着在此之前主要受内存带宽的限制 , 而计算大多处于空闲状态 。
一开始 FLOPS 的值是 0.2 teraflops 。 当我们将计算强度加倍时 , 这个数字会线性增长 , 直到接近 9.75 teraflops 的峰值 , 一旦接近峰值 teraflops 就被认为是「计算受限的」 。
最后 , 可以看到内存带宽从峰值附近开始 , 随着我们增加计算强度开始下降 。 这正是我们所期待的 , 因为这说明执行实际计算的时间越来越多 , 而不是访问内存 。
在这种情况下 , 很容易看出何时受计算限制以及何时受内存限制 。 repeat< 32 时 , 内存带宽接近饱和 , 而未进行充分的计算;repeat> 64 时 , 计算接近饱和(即接近峰值 FLOPS) , 而内存带宽开始下降 。
对于较大的系统 , 通常很难说是受计算限制还是内存带宽限制 , 因为它们通常包含计算限制和内存限制两方面的综合原因 。 衡量计算受限程度的一种常用方法是计算实际 FLOPS 与峰值 FLOPS 的百分比 。
然而 , 除了内存带宽成本之外 , 还有一件事可能会导致 GPU 无法丝滑运行 。
额外开销
当代码把时间花费在传输张量或计算之外的其他事情上时 , 额外开销(overhead)就产生了 , 例如在 Python 解释器中花费的时间、在 PyTorch 框架上花费的时间、启动 CUDA 内核(但不执行)所花费的时间 ,这些都是间接开销 。
额外开销显得重要的原因是现代 GPU 的运算速度非常快 。 A100 每秒可以执行 312 万亿次浮点运算(312TeraFLOPS) 。 相比之下 Python 实在是太慢了 ——Python 在一秒内约执行 3200 万次加法 。
这意味着 Python 执行单次 FLOP 的时间 , A100 可能已经运行了 975 万次 FLOPS 。
更糟糕的是 , Python 解释器甚至不是唯一的间接开销来源 , 像 PyTorch 这样的框架到达 actual kernel 之前也有很多层调度 。 PyTorch 每秒大约能执行 28 万次运算 。 如果使用微型张量(例如用于科学计算) , 你可能会发现 PyTorch 与 C++ 相比非常慢 。
例如在下图中 , 使用 PyTorch 执行单次添加 , 仅有一小块图是实际执行计算的内容 , 其他的部分都是纯粹的额外开销 。
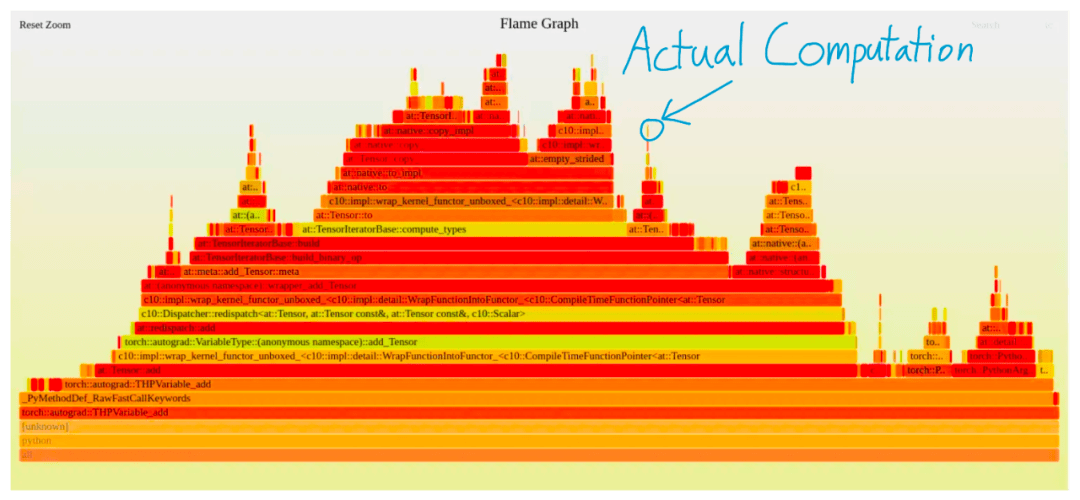
文章图片
鉴于此 , 你可能会对 PyTorch 成为主流框架的现象感到不解 , 而这是因为现代深度学习模型通常执行大规模运算 。 此外 , 像 PyTorch 这样的框架是异步执行的 。 因此 , 大部分框架开销可以完全忽略 。
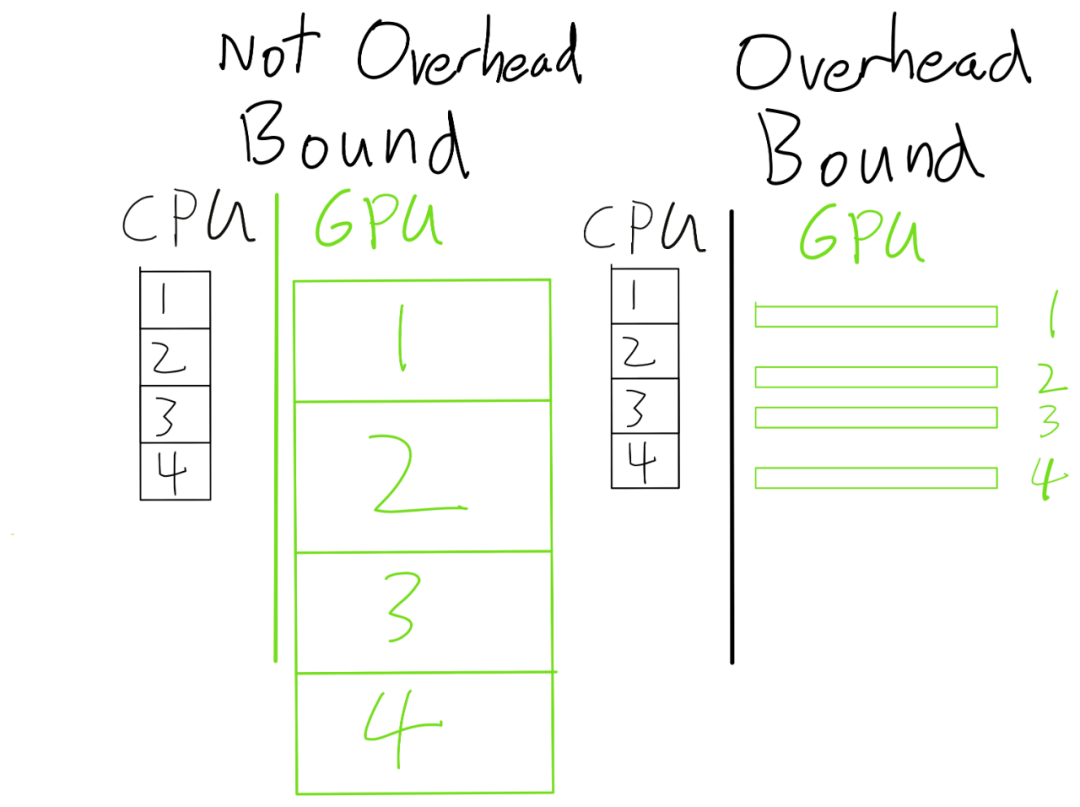
文章图片
如果我们的 GPU 算子足够大 , 那么 CPU 可以跑在 GPU 之前(因此 CPU 开销是无关紧要的) 。 另一方面 , 如果 GPU 算子太小 , 那么 GPU 将在 paperweight 上花费大部分时间 。
那么 , 如何判断你是否处于这个问题中?由于额外开销通常不会随着问题的规模变化而变化(而计算和内存会) , 所以最简单的判断方法是简单地增加数据的大小 。 如果运行时间不是按比例增加 , 应该可以说遇到了开销限制 。 例如 , 如果将批大小翻倍 , 但运行时间仅增加 10% , 则可能会受到开销限制 。
另一种方法是使用 PyTorch 分析器 。 如下图 , 粉红色块显示了 CPU 内核与 GPU 内核的匹配情况 。
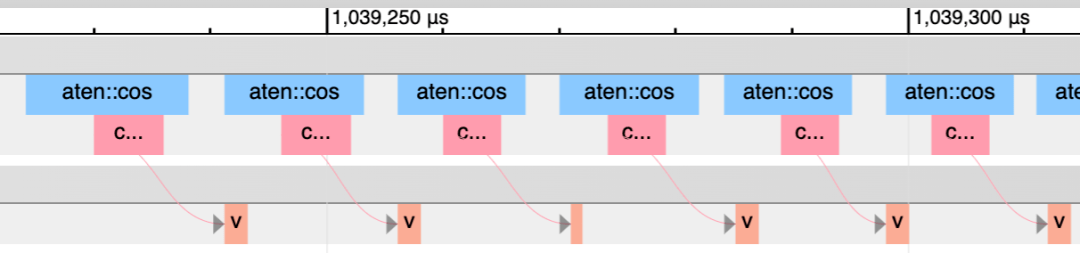
文章图片
CPU 运行地比 GPU 更超前 。
另一方面 , nvidia-smi 中的「GPU-Util」(不是「Volatile GPU-Util」)入口会测量实际运行的 GPU 内核的百分占比 , 所以这是另一种观察是否遇到开销限制的好方法 。 这种开销是 PyTorch 等所有灵活的框架所具有的 , 本质上都需要花费大量时间来「弄清楚要做什么」 。
这可能来自 Python(查找属性或调度到正确的函数)或 PyTorch 中的代码 。 例如 , 当你执行 a + b 时 , 需要执行以下步骤:
- Python 需要在 a 上查找__add__调度到的内容 。
- PyTorch 需要确定张量的很多属性(比如 dtype、device、是否需要 autograd)来决定调用哪个内核 。
- PyTorch 需要实际启动内核 。
不幸的是 , 这是以失去灵活性为代价的 。 一种两全其美的方法是 , 通过在 VM 级别进行 introspect 来编写更多符合「真实」的 JIT 的内容 。 有关更多信息 , 可参阅 TorchDynamo (https://dev-discuss.pytorch.org/t/torchdynamo-an-experiment-in-dynamic-python-bytecode-transformation/361) 。
总结
如果你想加速深度学习系统 , 最重要的是了解模型中的瓶颈是什么 , 因为瓶颈决定了适合加速该系统的方法是什么 。
很多时候 , 我看到研究人员和其他对加速 PyTorch 代码感兴趣的人 , 会在不了解所处问题的情况下盲目尝试 。

文章图片
当然 , 另一方面 , 如果用户需要考虑这些东西 , 也反映了框架的部分失败 。 尽管 PyTorch 是一个活跃的关注领域 , 但 PyTorch 的编译器或配置文件 API 并不是最容易使用的 。
总而言之 , 我发现对系统基本原理的理解几乎总是有用的 , 希望这对你也有用 。
原文链接:https://horace.io/brrr_intro.html
推荐阅读







- 通信|千兆护航 防疫有我|通信保障响应有速度!他们用科技点亮战“疫”
- 原因|飞机失事为什么一定要找到黑匣子?
- 技术|Keep春响聚焦三大运动场景 用智能技术助力全民健身
- 瑰宝|活态传承 国宝“破圈”——我国文化遗产活化利用观察
- 材料|什么是光固化3d打印机?光固化3d打印机的成型原理?
- 三家|工信部:截至2月末5G手机用户达3.84亿户 5G基站总数达150.6万个
- IT|国内首次大规模使用辉瑞新冠特效药
- 长三角|上海印发5G应用“海上扬帆”行动计划
- 声音|坠机事故为什么要找到黑匣子?
- 网络|6G从愿景阐释走向商用价值探索