风险|筛选风险词、用实体类型推断限售商品,阿里安全夺冠知识图谱大赛( 二 )
一方面是弱监督 。 通过外部高置信度的数据 , 训练模型 , 回标训练集 。 使用到的外部数据有维基百科、CN-DBpedia 。 其中 , 维基百科中的实体都是带有实体标签的 , 比如通过的标签映射中国男歌手即「人物 > 文艺工作者 > 歌手」, 即可得到外部的歌手数据 。
通过此种方法 , 得到的外部数据共计 30 万条 。 给定树状结构标签 , 广度优先 + 剪枝进行递归遍历 , 获取每个子类别 。 利用类似的方法 , 在 CN-DBpedia 中得到数据 70 万条 。
另一方面是基于句法分析标签抽取 。 通过分析训练数据 , 基于统计结果 , 大部分实体的首句 , 都包含了实体类型 。 基于 LTP 依存句法分析和语义角色标注的事件三元组抽取 , 可抽取出 (海贼王, 是 ,漫画) 。 通过此部分逻辑 , 可给 Train 打标 20 万条数据 。
文章图片
模型
基准
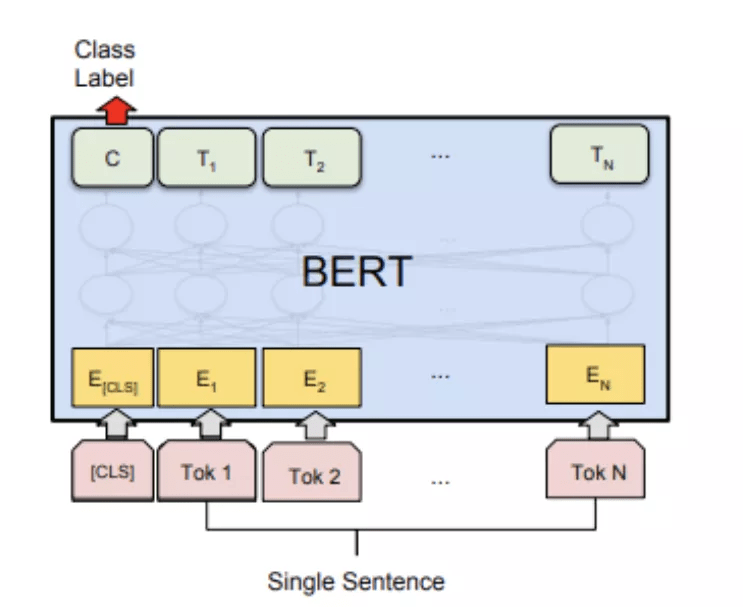
实体类型推断任务 , 本质上是一个文本的多分类任务 , 因此在模型的选择上 , 采用了预训练模型 + finetune 的方式作为基准(baseline) 。
文章图片
特征选择
需要分类的实体 , 本身包含名称、正文内容、多个属性对和关键词等特征 。 为了挑选出最佳的特征组合 , 阿里安全进行多组对照试验 , 最终得出结论:输入为「实体名 + 数据源 + 摘要 + 属性名 + 关键词」效果最好 。
预训练模型
阿里安全尝试了多种预训练模型 , 其中 Roberta-large 效果最好 。
层级损失
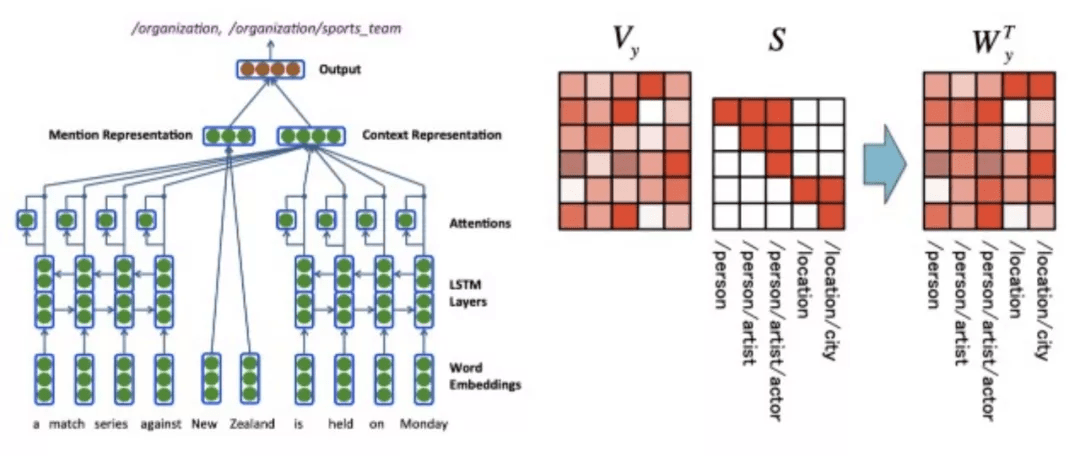
越细粒度的类别 , 父子标签所占的比重应该是不一样的 。 例如 , 如果选择了子标签 , 那么较粗的粒度肯定要选择父标签 , 而传统的损失函数在优化时 , 就是将它们平等对待的 。 因此 , 引入了层次分类最常用的几种损失 , 有效地解决了上述问题 , 并选用层级损失(Hierarchy loss)作为最终方案 。
文章图片
层级标签示意图
模型数据相互迭代优化方案
该方案类似于强化学习的思想 , 模型和数据相互正向优化 , 直至收敛 。 以游戏为例 , 通常会出现游戏类型这样的 schema 字段 , 反之 , 若一个实体若出现游戏类型 , 则大概率是游戏 。 类似游戏类型这样的 schema 或 keyword , 称之为「必杀」特征 。 这种方式类似漏斗 , 可以通过必杀属性 , 进而过滤出具体类别的实体 , 如下图所示:
【风险|筛选风险词、用实体类型推断限售商品,阿里安全夺冠知识图谱大赛】
推荐阅读







- AI财经社|“元宇宙第一股”来了:赚钱能力存疑,行业风险未知
- IT|加拿大研究显示因感染新冠病毒住院的儿童出现严重并发症的风险较高
- IT|一图速览全国各地出行政策:多地要求低风险地区返乡也需核检
- 媒体播放器|B站发布公告 将集中治理低俗类词语
- 警告!|专家:新兴娱乐方式快速发展 或给青少年带来社交、安全等风险
- 液氮|组织研磨仪词厂家教你含氟特性样品的研磨实验如何高质量研磨处理
- 风险|莫给虚拟货币“矿场”留空间
- 词频|18世纪就有GTA?词频统计器里的另一部“近现代史”
- 社交|瑞士军队放弃WhatsApp并转投Threema以规避境外数据管辖风险
- 奥秘|有望助力识别潜在疾病风险!复旦大学和中科院团队发现指纹基因奥秘