模型|轻量级TorchShard库减少GPU内存消耗,API与PyTorch相同
选自medium
作者:Kaiyu Yue
机器之心编译
编辑:陈
训练大模型时 , 如何优雅地减少 GPU 内存消耗?你不妨试试这个 TorchShard 库 , 兼具模型并行与数据并行等特点 , 还具有与 PyTorch 相同的 API 设计 。模型并行性能够促进视觉任务的性能 。 但是目前 , 还没有一个标准库可以让我们像采用混合精度等其他 SOTA 技术那样轻松地采用模型并行性 。
最近 , 马里兰大学帕克分校计算机科学系的研究者 Kaiyu Yue 开源了一个工具TorchShard , 这是一个轻量级的引擎 , 用于将 PyTorch 张量切片成并行的 shard 。 当模型拥有大量的线性层(例如 BERT、GPT)或者很多类(数百万)时 , TorchShard 可以减少 GPU 内存并扩展训练规模 , 它具有与 PyTorch 相同的 API 设计 。

文章图片
项目地址:https://github.com/KaiyuYue/torchshard
BERT 和 GPT 等超大模型正在成为 NLP 领域应用中的趋势 。 然而训练这种大模型面临内存限制的问题 , 为了解决这个难题 , 研究者使用 Megatron-LM 和 PyTorch-Lightning 模型并行性扩大训练 。 其中 , Megatron-LM 只专注于大规模训练语言模型 , 而 PyTorch-Lightning 仅基于 sharded 优化器状态和梯度 , 如 DeepSpeed 。
在计算机视觉任务中 , 我们会在训练基于 Transformer、MLP 模型或在数百万个类中训练模型时遇到同样的问题 。 TorchShard 的目标是:
- 建立一个标准的 PyTorch 扩展库 , 用于使用模型并行性进行扩展训练;
- 以一种简单、自然的方式使用 PyTorch 。
import torchshard as ts
ts.init_process_group(group_size=2) # init parallel groups
m = torch.nn.Sequential(
torch.nn.Linear(20, 30, bias=True),
ts.nn.ParallelLinear(30, 30, bias=True, dim=None), # equal to nn.Linear()
ts.nn.ParallelLinear(30, 30, bias=True, dim=0), # parallel in row dimension
ts.nn.ParallelLinear(30, 30, bias=True, dim=1), # parallel in column dimension
).cuda()
x = m(x) # forward
loss = ts.nn.functional.parallel_cross_entropy(x, y) # parallel loss function
loss.backward() # backward
torch.save(
ts.collect_state_dict(m, m.state_dict()), 'm.pt') # save model state
除此之外 , TorchShard 还支持与 DDP 一起使用时的各种特性 , 保存和加载 shard checkpoints , 初始化 shard 参数 , 以及跨多台机器和 GPU 处理张量 。 具体如下:
- torchshard 包含必要的功能和操作 , 如 torch 包;
- torchshard.nn 包含图形的基本构建块 , 如 torch.nn 包;
- torchshard.nn.functional 包含 torchshard.nn 的相应功能操作 , 如 torch.nn.functional 包;
- torchshard.distributed 包含处理分布式张量和组的基本功能 , 如 torch.distributed 包更容易使用 。
安装要求:Python 版本 3.6 以上(含)以及 PyTorch 版本 1.9.0 以上(含) 。 通过 pip 安装 TorchShard 库:
pip install torchshard
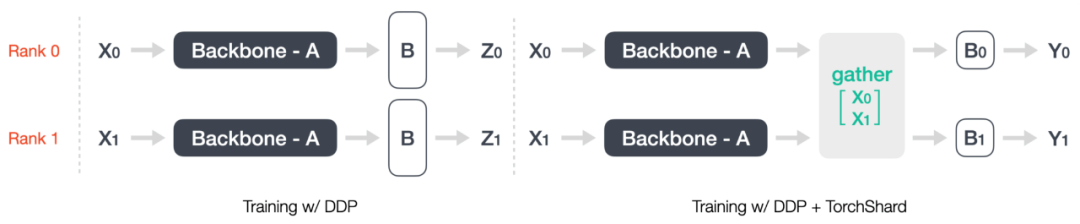
这里以 ImageNet 上训练 ResNet-50 为例 , 展示仅需几行代码就能在项目中使用 TorchShard 。 通常 ResNet-50 设计范式包含两部分:卷积块和全连接层 , 如下图 1 所示 。 一般来说 , 由于大量的类依赖于数据集 , 最后的线性层比卷积块有更多的参数 。 所以我们切片最后一个线性层来检查其最大尺寸 。
图 1:DDP 以及 DDP + TorchShard 前向训练流 。
文章图片
在上图 1 中 , 左边展示了传统的 DDP 训练范式 。 假设我们有两个等级 , DDP 将强制每个等级有重复的模型参数 。 然而 , TorchShard 会将层级参数切片到不同的等级 , 从而减少整个 GPU 内存 。 现在向 ImageNet 官方训练脚本添加一些代码 , 修改后的版本已经成为 TorchShard 项目的一部分 。
首先将 torchshard import 进来:
import torchshard as ts
然后需要初始化模型并行的进程组 , 就像初始化 DDP 进程组的方法一样 。 只需要设置一个功能参数来告诉 torchshard 应该从目标层中切片出多少个 shard 。
ts.distributed.init_process_group(group_size=args.world_size)
接下来将模型转换为并行版本 , 其中可以直接将整个模型输入到转换辅助函数中 , 无需特殊处理 。
import resnet
model = resnet.__dict__[args.arch](pretrained=args.pretrained)
ts.nn.ParallelLinear.convert_parallel_linear(
model, dim=args.model_parallel_dim
print("=> paralleling model'{}'".format(args.arch))
此外 , 不要忘记损失函数 torchshard.nn.ParallelCrossEntropy, 该损失函数可以根据输入张量在原始 PyTorch 版本和并行版本之间切换运行模式 。 例如 , 如果输入张量是由 torchshard 并行层产生的 , torchshard.nn.ParallelCrossEntropy 将以并行方式计算损失值 。
criterion = ts.nn.ParallelCrossEntropyLoss().cuda(args.gpu)
当模型并行模式(TorchShard)和数据并行模式(DDP)一起工作时 , 我们需要处理并行层的输入 。 每个等级中的参数和训练数据都不同 。 因此 , 我们在 ResNet forward 中的并行线性层之前收集输入张量 。
x = ts.distributed.gather(x, dim=0) # gather input along the dim of batch size
x = self.fc(x)
同样地 , 我们在计算损失值之前收集目标张量 。
output = model(images)
if args.enable_model_parallel:
target = ts.distributed.gather(target, dim=0)
loss = criterion(output, target)
最后 , 使用 TorchShard 函数保存和加载 checkpoints 非常简单 。 TorchShard 提供了名为 torchshard.collect_state_dict 基本函数用于保存 checkpoints , torchshard.relocate_state_dict 用于加载 checkpoints 。
保存检查点:
state_dict = model.state_dict()
# collect states across all ranks
state_dict = ts.collect_state_dict(model, state_dict)
if ts.distributed.get_rank() == 0:
torch.save(state_dict, 'resnet50.pt') # save as before
加载检查点:
if ts.distributed.get_rank() == 0:
state_dict = torch.load('resnet50.pt')
# relocate state_dict() for all ranks
state_dict = ts.relocate_state_dict(model, state_dict)
model.load_state_dict(state_dict) # load as before
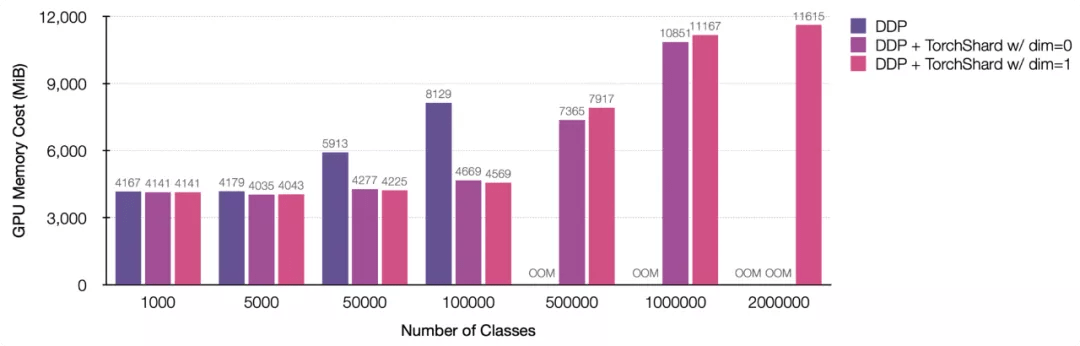
现在我们已经完成了在 ImageNet 上为 shard 训练添加代码 ,然后可以通过增加类的数量来扩展它 , 即最后一个线性层的输出特征维度 。 训练脚本可以在 torchshard/project/imagenet 中找到 。 下图展示了在 8 个 NVIDIA TITAN-XP (12196 MiB) GPU 、类数 ≤ 1000000 上和 16 个 GPU 、类数为 2000000 上训练 ResNet-50 扩展能力 。
图 2:在不同并行策略下使用标准 ResNet 训练设置(即输入大小 224 和批量大小 256)的 GPU 内存成本 。
文章图片
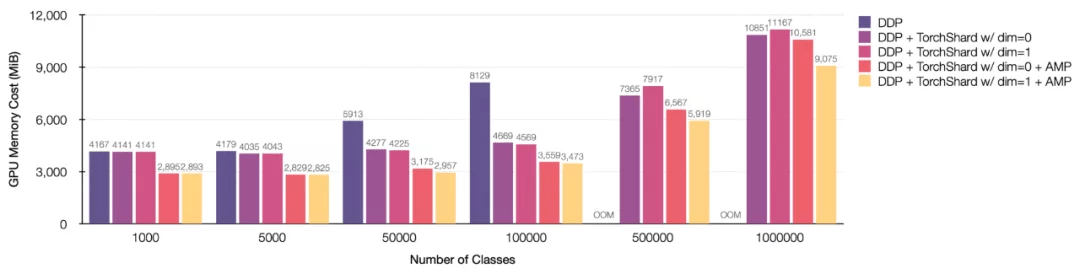
使用 AMP 与 ZeRO
TorchShard 以简单自然的 PyTorch 方式与其他技术(例如自动混合精度 AMP 以及 ZeRO)一起混合使用 。
# gradscaler
scaler = torch.cuda.amp.GradScaler(enabled=args.enable_amp_mode)
with torch.cuda.amp.autocast(enabled=args.enable_amp_mode): # compute output
output = model(images)
if args.enable_model_parallel:
target = ts.distributed.gather(target, dim=0)
loss = criterion(output, target)
# compute gradient and do SGD step
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
optimizer.zero_grad()
文章图片
图 3:在不同并行策略以及 AMP 下 , 使用标准的 ResNet 训练设置时(输入尺寸 224 , batch 大小 256) , 使用 GPU 内存的成本 。
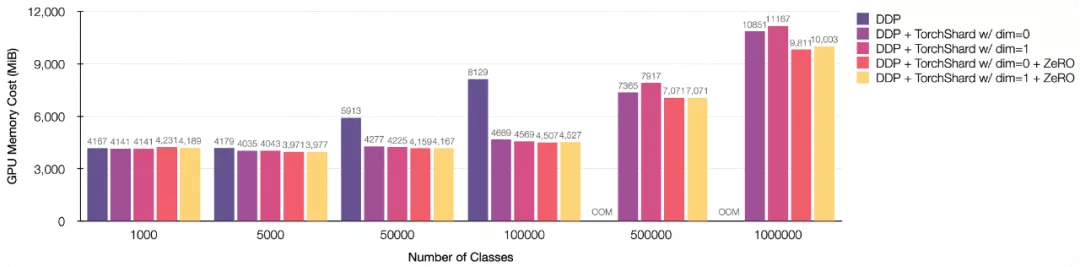
ZeRO 是 DeepSpeed 的核心 , 与 PyTorch >= 1.9.0 一起使用 。 如果你想测试一个函数 , 请安装最新版本的脚本来运行 , 代码如下:
from torch.distributed.optim import ZeroRedundancyOptimizer
if args.enable_zero_optim:
print('=> using ZeroRedundancyOptimizer')
optimizer = torch.distributed.optim.ZeroRedundancyOptimizer(
model.parameters(),
optimizer_class=torch.optim.SGD,
lr=args.lr,
momentum=args.momentum,
weight_decay=args.weight_decay)
else:
optimizer = torch.optim.SGD(model.parameters(), args.lr,
momentum=args.momentum,
weight_decay=args.weight_decay)
文章图片
【模型|轻量级TorchShard库减少GPU内存消耗,API与PyTorch相同】图 4:在不同的并行策略和 ZeRO 优化器下 , 在标准 ResNet 训练设置(输入大小 224 和批大小 256)的 GPU 内存成本 。
此外 , TorchShard 还提供了基本的 Python API 以及和相应的模板文件 , 以简化自定义并行层的实现 。
研究者将持续开发 TorchShard , 如 TorchShard 下一个特性是新的数据采样器 torchshard.utils.data.DistributedGroupSampler , 它的命名遵循 torch.utils.data.DistributedSampler 。 该采样器旨在帮助用户构建 M-way 数据并行、N-way 模型并行 , 使得其就像 DDP 中的 DistributedSampler 一样简单 。 用户唯一要做的就是设置模型并行组号 , 然后 DistributedGroupSampler 来确保同一模型并行组中的模块具有相同的训练数据 。
原文链接:https://medium.com/pytorch/torchshard-a31fcbfdc354
推荐阅读







- 模型|2022前展望大模型的未来,周志华、唐杰、杨红霞这些大咖怎么看?
- 模型|经逆向工程,Transformer「翻译」成数学框架 | 25位学者撰文
- 化纤|JXK STUDIO 虎年肥猫 1/6仿真动物模型手办可爱摆件
- 模型|达摩院2022十大科技趋势发布:人工智能将催生科研新范式
- 模型|李彦宏:中国迎来AI黄金十年,集度汽车机器人明年亮相,智能交通10年内解决拥堵
- 模型|神经辐射场去掉「神经」,训练速度提升100多倍,3D效果质量不减
- 模型|英伟达:美团机器学习平台使用NVIDIA T4 GPU
- 错误|有了这个工具,不执行代码就可以找PyTorch模型错误
- the|美国大学模型预测:全美未来两月或激增1.4亿确诊
- Samsung|三星Galaxy S22系列模型照片出现 S Pen颜色确认