分析|拓端数据tecdat:R语言分布滞后线性和非线性模型(DLMs和DLNMs)分析时间序列
原文链接:http://tecdat.cn/?p=20953 序言
本文演示了在时间序列分析中应用分布滞后线性和非线性模型(DLMs和DLNMs) 。 Gasparrini等人[2010]和Gasparrini[2011]阐述了DLMs和DLNMs的发展以及时间序列数据的实现 。 本文描述的示例涵盖了时间序列数据DLNM方法的大多数标准应用 , 并探讨了DLNM包用于指定、总结和绘制此类模型 。 尽管这些例子在空气污染和温度对健康的影响方面有具体的应用 , 但它们很容易被推广到不同的主题 , 并为分析这些数据集或其他时间序列数据源奠定了基础 。
数据 示例使用时间序列数据集(包括1987-2000年期间每日观测数据)探索了空气污染和温度与死亡率之间的关系 。 在R会话中加载后 , 让我们看一下前三个观察结果:
- date time year month doy dow death cvd resp temp dptp
- 1 1987-01-01 1 1987 1 1 Thursday 130 65 13 -0.2777778 31.500
- 2 1987-01-02 2 1987 1 2 Friday 150 73 14 0.5555556 29.875
- 3 1987-01-03 3 1987 1 3 Saturday 101 43 11 0.5555556 27.375
- rhum pm10 o3
- 1 95.50 26.95607 4.376079
- 2 88.25 NA 4.929803
- 3 89.50 32.83869 3.751079
示例1:一个简单的DLM 在第一个例子中 , 我指定了一个简单的DLM , 评估PM10对死亡率的影响 , 同时调整温度的影响 。 我首先为这两个预测值建立两个交叉基矩阵 , 然后将它们包含在回归函数的模型公式中 。 假设PM10的影响在预测因子的维度上是线性的 , 因此 , 从这个角度来看 , 我们可以将其定义为一个简单的DLM , 即使回归模型也估计了温度的分布滞后函数 , 这是一个非线性项 。 首先 , 我运行crossbasis()来构建两个交叉基矩阵 , 将它们保存在两个对象中 。 两个对象的名称必须不同 , 以便分别预测它们之间的关联 。 代码如下:
- cb(pm10, lag=15, argvar=list(fun="lin",
- arglag=list(fun="poly",degree=4
- CROSSBASIS FUNCTIONS
- observations: 5114
- range: -3.049835 to 356.1768
- lag period: 0 15
- total df: 5
- BASIS FOR VAR:
- fun: lin
- intercept: FALSE
- BASIS FOR LAG:
- fun: poly
- degree: 4
- scale: 15
- intercept: TRUE
- glm(death ~ cb1.pm + cb1.temp + ns(time, 7*14) + dow,
- family=quasipoisson()
pred(cb1.pm, model1, at=0:20, bylag=0.2, cumul=TRUE)
该函数包括用来估计参数的base1.pm和model1对象作为前两个参数 , 而at = 0:20表示必须为从0到20 μgr / m3的每个整数值计算预测 。 通过设置by lag = 0.2 , 沿着滞后空间以0.2的增量计算预测 。 绘制结果时 , 此更精细的网格产生更平滑的滞后曲线 。 参数cumul(默认为FALSE)指示还必须包括沿滞后的增量累积关联 。 没有通过参数cen定义中心 , 因此默认情况下将参考值设置为0(这种情况发生在函数lin()上) 。 现在 , 这些预测已存储在pred1.pm中 , 可以通过特定的方法对其进行绘制 。 例如:
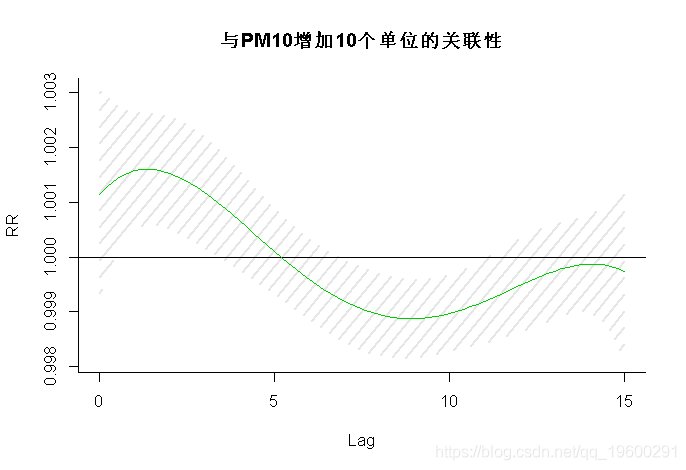
- > plot(pred1, "slices",
- main="与PM10增加10个单位的关联性")
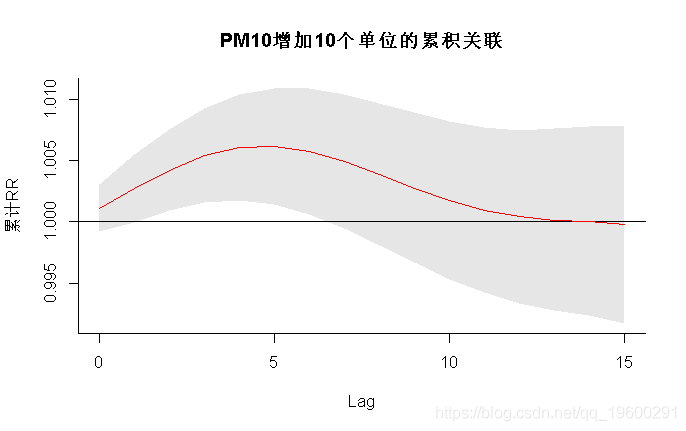
- > plot(pred1,ylab="累计RR",
- main="PM10增加10个单位的累积关联")
文章图片
文章图片
该函数包含带有存储结果的pred1.pm对象 , 参数“slices”定义了我们要绘制对应于相关维度中predictor和lag的特定值的关系图 。 var=10时 , 我显示PM10特定值的滞后响应关系 , 即10μgr/m3 。 该关联使用0μgr/m3的参考值来定义 , 从而为10个单位的增加提供预测特定关联 。 我还为第一个图选择了不同的颜色 。 PM10的特定值 , 即10 μgr / m3 。 使用0 μgr / m3的参考值定义此关联 , 从而为增加10个单位提供了特定于预测变量的关联 。 我还为第一个图选择了不同的颜色 。 参数cumul指示是否必须绘制以前保存在pred1.pm中的增量累积关联 。 结果如图1a-1b所示 。 置信区间被设置为参数ci的默认值“ area” 。 在左面板中 , 其他参数通过ci.arg传递给绘图函数polygon() , 绘制阴影线作为置信区间 。 对这些曲线图的解释有两个方面:滞后曲线表示特定日期PM10增加10μgr/m3后未来每一天的风险增加(正向解释) , 或者过去每一天相同PM10对特定日期风险增加的贡献(反向解释) 。 图1a-1b中的曲线图表明 , PM10风险的初始增加在较长的滞后时间被逆转 。 PM10在15天滞后时间内增加10个单位的总体累积效应(即将所有贡献相加至最大滞后时间)及其95%置信区间可通过pred1.pm中包含的对象allRRfit、allRRhigh和allRRlow提取 , 键入:
- > pred1
- 10
- 0.9997563
- > cbind(pred1.p
- [1] 0.9916871 1.0078911
Sseas <- subset(NMMAPS, month %in% 6:9)
同样 , 我首先创建交叉基矩阵:
- cb(o3, lag=5,
- argvar=list(fun="thr",thr=40.3), arglag=list(fun="integer"),
- group=year)
- glm(death ~ cb2.o3 + cb2.temp + ns(doy, 4) + ns(time,3) + dow,
- family=quasipoisson())
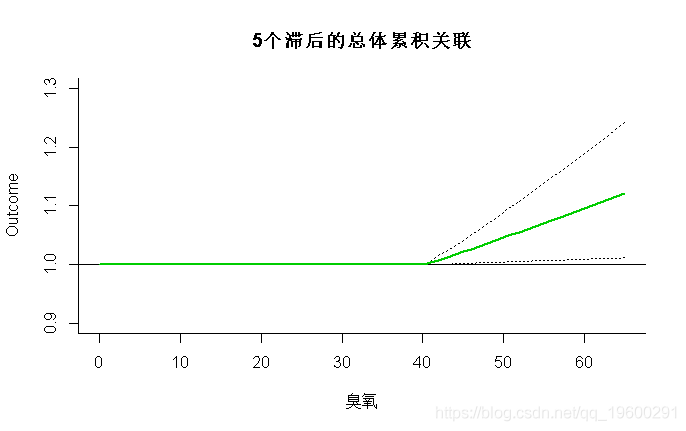
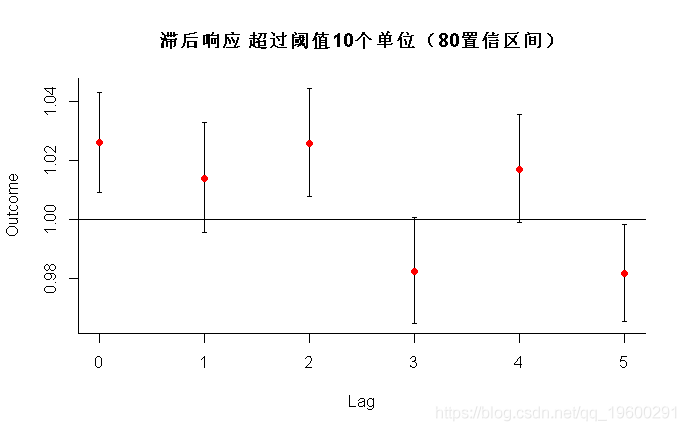
- > plot(pred2.o3, "slices", main="滞后响应 超过阈值10个单位"(80置信区间))
- > plot(pred2.o3,"overall",xlab="臭氧", ci="l", main="5个滞后的总体累积关联")
- > pred2.o3$allRRfit["50.3"]
- 50.3
- 1.047313
文章图片
文章图片
- > cbind(allRRlow, allRRhigh)["50.3",]
- [1] 1.004775 1.091652
示例3:二维DLNM 在前面的例子中 , 空气污染(分别为PM10和O3)的影响被假定为完全线性或高于阈值的线性 。 这一假设有助于解释和表示这种关系:从不考虑预测因子的维度 , 并且很容易绘制出10个单位增加的特定或总体累积关联 。 相反 , 当考虑到温度的非线性相关性时 , 我们需要采用二维透视图来表示沿预测变量空间和滞后量非线性变化的关联 。 在此示例中 , 我指定了一个更复杂的DLNM , 其中使用两个维度的平滑非线性函数来估计相关性 。 尽管关系的复杂性更高 , 但我们将看到指定和拟合模型以及预测结果所需的步骤与之前看到的简单模型完全相同 , 只需要选择不同的绘图即可 。 用户可以采用相同的步骤来研究先前示例中的温度影响 , 并扩展PM10和O3的图 。 在这种情况下 , 我运行DLNM来研究温度和PM10对死亡率的影响 , 分别达到滞后30和1 。 首先 , 我定义了交叉基矩阵 。 特别是 , 温度的交叉基是通过自然和非自然样条曲线指定的 , 使用来自软件包样条曲线的函数ns()和bs() 。 代码如下:
- > varknots <- equalknots(temp,fun="bs",df=5,degree=2)
- > lagknots <- logknots(30, 3)
- > plot(pred3.temp, xlab="温度" lphi=30,
- main="温度效应的3D图")
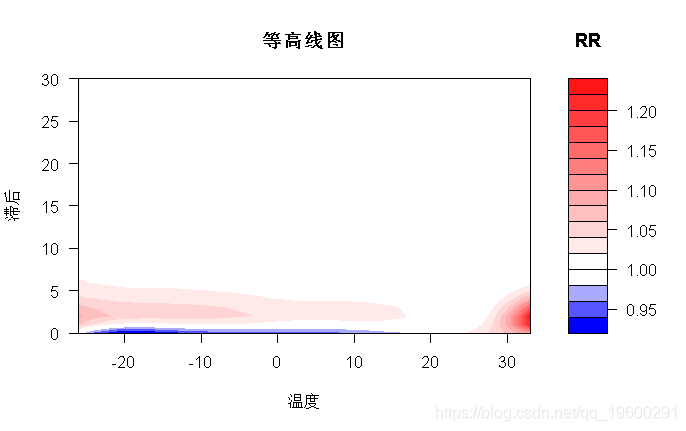
- > plot(pred3.temp, "contour", xlab="温度",
- plot.title=title("等高线图",xlab="温度",ylab="滞后"))
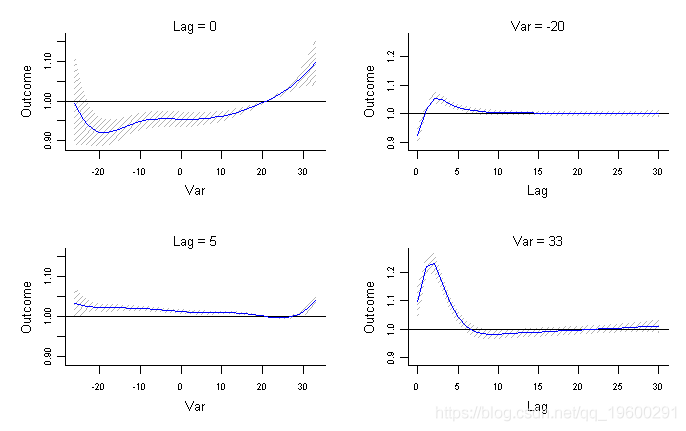
- > plot(pred3.temp, "slices", var=-20,
- main="不同温度下的滞后反应曲线 , 参考21C")
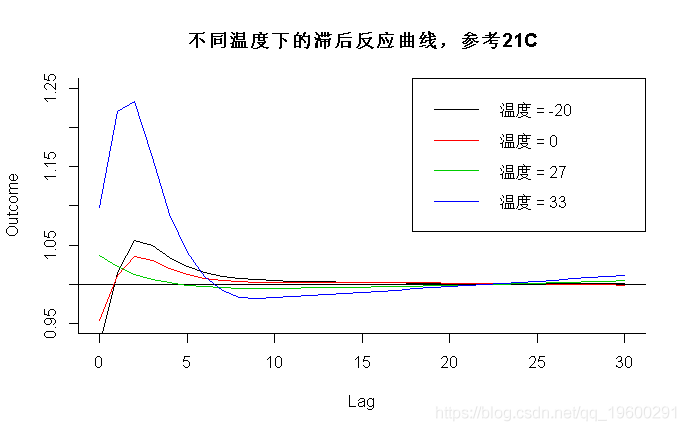
- > for(i in 1:3) lines(pred3.temp, "slices", var=c(0,27,33)[i]
- > legend("topright",paste("温度 ="

文章图片
文章图片
结果如图4a-4b所示 。 图4a说明了特定于-20℃、0℃、27℃和33℃的温和和极端冷热温度(参考21℃)的滞后反应曲线 。 图4b
文章图片
文章图片
描述了滞后0和滞后5的暴露-反应关系(左列)以及温度-20℃和33℃下的滞后-反应关系(右列) 。 参数var和lag定义了要在图3a-3b中的效果表面上切割的“切片”的温度和滞后值 。 第一个表达式中的参数ci =“ n”表示不能绘制置信区间 。 在多面板图4b中 , 列表参数ci.arg用于绘制置信区间 , 将其作为阴影线增加灰色对比度 , 在此处更加明显 。 初步解释表明 , 低温比高温具有更长的死亡风险 , 但不是立即的 , 在滞后0时显示出“保护”效应 。 这种分析能力很难用更简单的模型实现 , 可能会丢失关联的重要细节 。
示例4:降维DLNM 在最后一个例子中 , 我展示了如何使用函数crossreduce()将二维DLNM的拟合度降低到由一维基的参数表示的摘要 。 首先 , 我指定一个新的交叉基矩阵 , 运行模型并以通常的方式进行预测
指定的温度交叉基由双阈值函数和自然三次样条组成 , 分别以10°C和25°C的截止点作为预测器的维数 , 以对数标度中相等间距的节点值作为滞后量 , 如前一示例所示 。 可以对3个特定的摘要进行归约 , 即总的累积 , 滞后特定和预测变量特定的关联 。 前两个代表暴露-反应关系 , 而第三个代表滞后-反应关系 。 代码如下:
credu(cb4, model4)
在滞后5℃和33℃时 , 分别在两个空间中计算关联的减少 。 “crossreduce”类的3个对象包含相关空间中一维基的修改缩减参数 , 可与原始模型进行比较:
- > length(coef(pred4))
- [1] 10
- > length(coef(redall)) ; length(coef(redlag))
- [1] 2
- [1] 2
- > length(coef(redvar))
文章图片
文章图片
正如预期的那样 , 对于预测变量的空间 , 参数数量已减少到2(与双阈值参数化一致) , 对于滞后空间 , 参数数量已减少到5(与自然三次样条曲线基的维度一致) 。 但是 , 原始拟合和简化拟合的预测是相同的 , 如图5a所示:
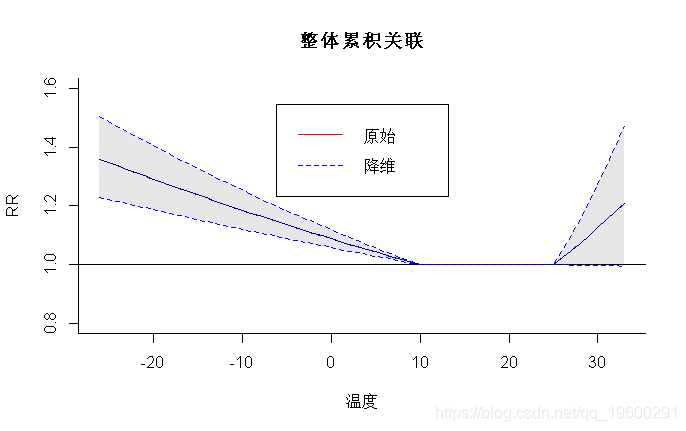
- > plot(pred4, "overall", xlab="温度", ylab="RR",
- ylim=c(0.8,1.6), main="整体累积关联")
- > lines(redall, ci="lines",col=4,lty=2)
- > legend("top",c("原始","降维"),col=c(2,4),lty=1:2,ins=0.1)
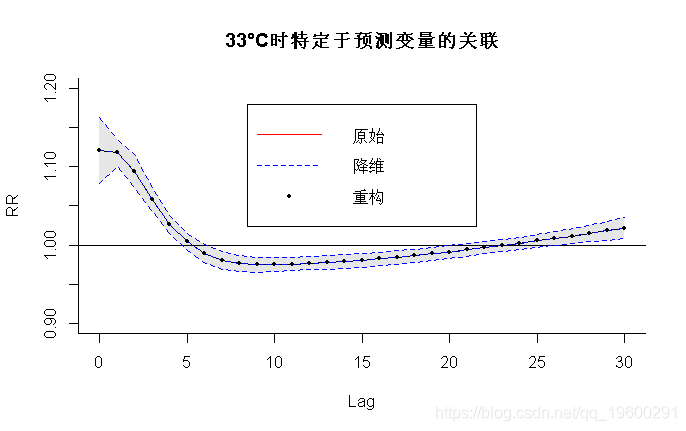
样条基是基于对应于滞后0:30的整数值计算的 , 节点与原始交叉基的值相同 , 并且不居中 , 以截距作为滞后基的默认值 。 使用修正后的参数对33℃的预测值进行计算 。 原始、简化和重建预测值的相同拟合如图5b所示 , 由以下公式得出:
- > plot(pred4, "slices", var=33,
- main="33°C时特定于预测变量的关联")
- > legend("top",c("原始","降维","重构"),

文章图片
最受欢迎的见解
1.在python中使用lstm和pytorch进行时间序列预测
2.python中利用长短期记忆模型lstm进行时间序列预测分析
3.使用r语言进行时间序列(arima , 指数平滑)分析
4.r语言多元copula-garch-模型时间序列预测
5.r语言copulas和金融时间序列案例
6.使用r语言随机波动模型sv处理时间序列中的随机波动
7.r语言时间序列tar阈值自回归模型
8.r语言k-shape时间序列聚类方法对股票价格时间序列聚类
9.python3用arima模型进行时间序列预测
推荐阅读







- 区块|面向2030:影响数据存储产业的十大应用(下):新兴应用
- 选型|数据架构选型必读:2021上半年数据库产品技术解析
- 殊荣|蝉联殊荣!数梦工场荣获DAMA2021数据治理三项大奖
- 数据|数智安防时代 东芝硬盘助力智慧安防新赛道
- Apple|摩根大通分析师:交货时间来看iPhone 13系列已达供需平衡
- 平台|数梦工场助力北京市中小企业公共服务平台用数据驱动业务创新
- 数据|中标 | 数梦工场以数字新动能助力科技优鄂
- 建设|数据赋能业务,数梦工场助力湖北省智慧应急“十四五”开局
- 市民|大数据、人工智能带来城市新变化 科技赋能深化文明成效
- 趋势|[转]从“智能湖仓”升级看数据平台架构未来方向