机器之心报道
机器之心编辑部
来学习下 OSDI 2021 的最佳论文 。OSDI(操作系统设计与实现研讨会 , Operating Systems Design and Implementation)是计算机系统软件领域全球最顶级的会议之一 , 被誉为「操作系统原理领域的奥斯卡」 , 拥有极高的学术地位 , 由 USENIX 主办 。
USENIX 成立于 1975 年 , 起初名字为 Unix 用户群 , 其主要目的是学习和开发 Unix 以及类似系统 , 后该用户群更名为「USENIX」 。 OSDI 汇集了来自学术和行业领域的专业人士 , 是探讨系统软件的设计、实现和影响的首要论坛 。
实际上 OSDI 所覆盖的领域已经远远超过操作系统 。 OSDI 是系统领域和 SOSP 并驾齐驱的两个顶级会议之一 , 机器学习经典框架 TensorFlow 最初就是发表于 OSDI 。 因此 OSDI 的获奖论文对于想深入系统领域的研究者来说是必读的 。
第 15 届 USENIX OSDI 于 2021 年 7 月 14 日至 16 日线上举行 , 日前最佳论文等奖项已经陆续公布 , 共有 3 篇最佳论文 , 来自卡内基 · 梅隆大学(CMU)邢波教授的研究团队摘得其中一篇 。 我们来看一下这 3 篇最佳论文的具体内容 。

文章图片
最佳论文
论文一:MAGE: Nearly Zero-Cost Virtual Memory for Secure Computation

文章图片
论文地址:https://people.eecs.berkeley.edu/~samkumar/papers/mage_osdi2021.pdf
安全计算(Secure Computation , SC)是指在单方和多方设置下 , 用于计算加密数据的一系列密码原语 。 尽管 SC 越来越多地被用于各种行业应用 , 但在实际应用中使用 SC 的一个重大障碍是底层加密的内存开销 。 该研究提出了一种新的 SC 执行引擎 MAGE , 在内存开销不合适的情况下也能够有效地执行 SC 计算 。 研究者观察到 , 由于其预期的安全保障 , SC 方案本质上是不经意的(oblivious)即其内存访问模式独立于输入数据 。 使用此属性 , MAGE 会提前计算内存访问模式 , 并使用此属性生成内存管理计划 。 这种内存管理形式 , 可称为内存编程 , 是分页的的一种泛化形式 , 允许 MAGE 为 SC 提供一个高效的虚拟内存抽象 。 MAGE 的性能比 OS 虚拟内存系统高出一个数量级 , 并且在许多情况下 , 运行不合适内存的 SC 计算速度与底层机器拥有无限物理内存来满足整个计算的速度几乎相同 。
如下图所示 , MAGE 的工作流程包含两个阶段 。 SC 应用程序是在 C++ 内部的 DSL 中编写的 。 MAGE 的 planner 将 DSL 代码展开以生成字节码 , 然后对字节码执行转换来生成内存程序 。
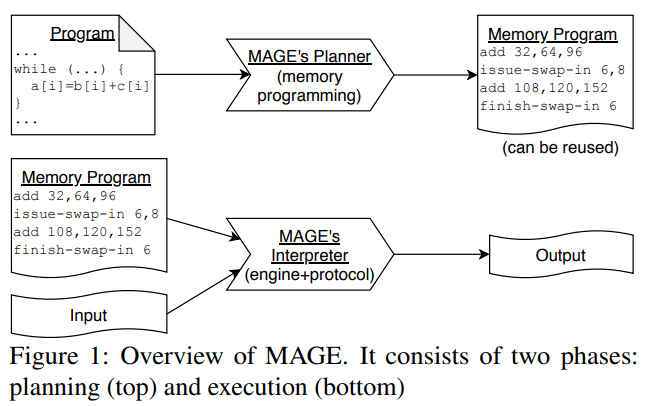
文章图片
MAGE 的 planner 工作流程分为三个阶段:布局、替换、调度 。
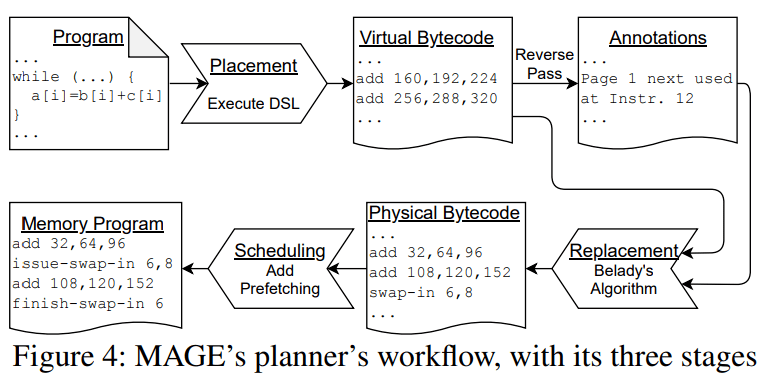
文章图片
论文二:Pollux: Co-adaptive Cluster Scheduling for Goodput-Optimized Deep Learning

文章图片
- 论文地址:https://www.pdl.cmu.edu/PDL-FTP/CloudComputing/osdi21-pollux.pdf
- 项目地址:https://github.com/petuum/adaptdl
该研究同时考虑了上述两个方面 , 并提出了一种名为 Goodput 的新指标 , 将系统吞吐量与统计效率相结合 。 通过在训练期间监控每个作业的状态 , Pollux 模拟了在添加和移除资源时每个作业的 Goodput 变化 。 利用这些信息 , Pollux 动态(重新)分配资源以提高 cluster-wide 的 goodput , 同时尊重公平性并不断优化每个深度学习作业 , 以更好地利用资源 。
在实际深度学习作业和轨迹驱动(trace-driven)模拟的实验中 , 相比于 SOTA 深度学习调度程序 , Pollux 将平均作业完成时间减少了 37-50% , 并为每个作业提供了理想的资源和训练配置 。 Pollux 基于对有用作业完成进度提出更有意义的衡量指标 , 来提升深度学习作业竞争资源的公平性 , 并揭示了在云环境下降低深度学习成本具有新机会 。
Pollux 的协同自适应调度架构 。
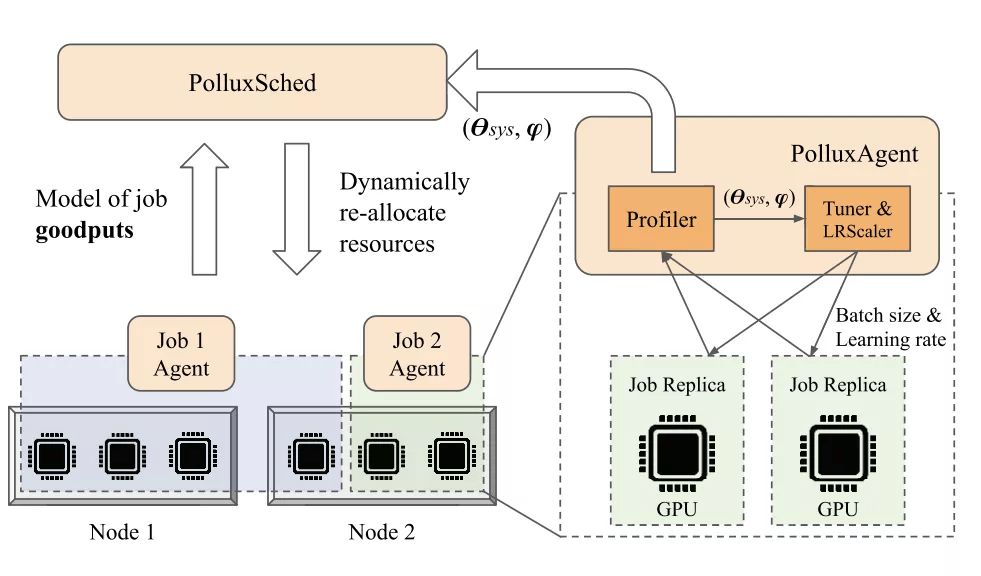
文章图片
论文三:DistAI: Data-Driven Automated Invariant Learning for Distributed Protocols

文章图片
论文地址:https://www.usenix.org/system/files/osdi21-yao.pdf
论文摘要:分布式系统很难正确实现 , 主要原因在于其不确定性 。 找到分布式协议的归纳不变式是验证分布式系统正确性的关键步骤 , 但即使是简单的分布式协议也需要花费很长的时间 。 该研究提出了 DistAI , 一个用于学习分布式协议归纳不变式的数据驱动自动化系统 。 DistAI 通过模拟不同实例大小的分布式协议并将状态记录为样本来生成数据 。 观察发现 , 不变式在实践中通常是比较简洁的 , DistAI 从小型不变式开始 , 并列举适用于所有样本的最强可能不变式 。 然后 , DistAI 将这些不变式和所需的安全属性提供给 SMT 求解器 , 以检查不变量和安全属性的结合是否归纳 。
从较小的不变式和可能的最强不变式开始 , 可以避免大型 SMT 查询 , 提高 SMT 求解器的性能 。 因为 DistAI 是从可能的最强不变式开始 , 如果 SMT 求解失败 , DistAI 也不需要丢弃失败的不变式 , 会单调弱化这些不变式 , 并用求解器再次尝试 , 重复该过程直到最终成功 。
该研究表明 DistAI 能够找到「?-free」归纳不变式 , 如果存在该不变式 , 则能证明在有限时间内存在所期望的安全属性 。 该研究的评估实验表明 , DistAI 成功地自动验证了 13 种常见的分布式协议 , 并在验证的协议数量和速度方面都优于其他常用方法 , 在某些情况下 , 它的速度超过其他方法两个数量级 。
下图为 DistAI 的工作流程 , 从 IVy 的分布式协议规范开始 , 首先 , DistAI 进行两阶段采样;其次 , DistAI 进行枚举操作;然后 , DistAI 将候选不变式提供给 IVy , IVy 要么成功地将不变式与所需的安全属性结合作为归纳不变式 , 要么失败并指出不成立的不变式;最后 , DistAI 执行单调优化 。
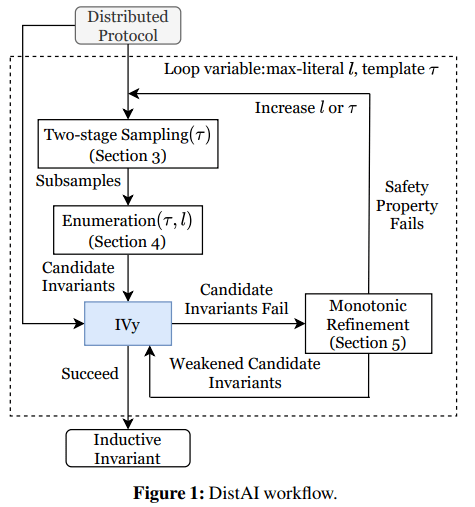
文章图片
【团队|计算机系统软件顶会OSDI 2021最佳论文出炉,邢波团队研究入选】举报
推荐阅读







- 智能化|龙净环保:智能型物料气力输送系统的研究及应用成果通过鉴定
- 识别|天津滨海机场RFID行李全流程跟踪系统完成建设 行李标签识别成功率可提升至99%
- 最新消息|IT系统出错 英国银行给7.5万人多发11亿工资
- IT|新航空图像拍摄系统Microballoon:可重复使用且成本更低
- 最新消息|宝马LG和其他公司正考虑使用量子计算机解决具体问题
- 公司|赣锋锂业智能立体仓储系统正式运行
- 系统验证|以技术革新加速芯片创新效率,EDA软件集成版PNDebug正式发布
- 核心|中科大陈秀雄团队成功证明凯勒几何两大核心猜想,研究登上《美国数学会杂志》
- VIA|x86研发团队卖给Intel后 VIA出售厂房和设备:北美分部就此终结
- 高通骁|一加 10 Pro 现身 Geekbench:搭载高通骁龙 8,运行安卓 12 系统