From:AI人工智能初学者
传统的目标检索任务很难检测现实世界的对象 , 由于没有边界框注释 , 物体级检索变得很棘手 , 这引出了图像搜索问题 。
为了解决这一问题 , 本文作者 介绍了一个端到端集成网(I-Net) , 并 进一步提出一种改进的I-Net , 称为DC-I-Net , 实验结果表明其优于最新的一些图像搜索模型 。
https://arxiv.org/abs/2009.01438
传统的目标检索任务旨在学习具有内部相似度和内部相异度的区分特征表示 , 它假设图像中的对象是手动或自动精确裁剪的 。 但是 , 在许多现实世界中的搜索场景(例如 , 视频监视)中 , 很少准确地检测或标注对象(例如 , 人、车辆等) 。 因此 , 在没有边界框注释的情况下 , 物体级检索变得很棘手 , 这导致了一个新的但具有挑战性的主题 , 即图像搜索 。
一、简介
行人搜索是图像搜索问题的第一个尝试 。 在此之前 , 虽然对人的检测和重识别做了大量的努力 , 但大多数都是独立处理这两个问题的 。 也就是说 , 传统方法将行人搜索任务划分为两个独立的子任务 。
首先 , 利用行人检测器从图像中预测人物的边界盒 , 然后根据预测的边界盒的坐标对被检测人物的矩形区域进行裁剪 。 其次 , 提取检测框内行人的特征用于重新识别人物 。
在一般的行人重识别(Re-ID)任务中 , 对行人图像进行人工注释和裁剪 , 然后用于训练的鉴别特征表示网络 。 一方面是因为在真实的视频监控任务中 , 大多数检测器不可避免地会出现误检和框选不准的情况 , 在一定程度上可能会导致ReID精度的性能显著下降 。 另一方面 , 这两个独立的子任务似乎对实际应用程序中的最终Re-ID不太友好 。

文章图片
图1 传统ReID+检索的过程和本文所提方法的对比图
在本文中 , 为了解决图像搜索问题 , 我们首先介绍一个端到端集成网(I-Net) , 它具有三个优点:
1. 通过设计Siamese架构来进行在线匹配相似和不相似样本对 。
2. 引入了新颖的在线配对(OLP)损失和动态特征字典 , 该字典通过自动生成多个负数对来限制正数 , 从而减轻了多任务训练停滞问题 。
3. 提出了一种Hard example priority(HEP)的softmax损失 , 以通过选择Hard类别来提高分类任务的鲁棒性 。
借助分而治之的理念 , 文章进一步提出了一种改进的I-Net , 称为DC-I-Net , 它做出了两个新的贡献:
1. 量身定制了两个模块以在集成框架中分别处理不同的任务 , 从而使任务规格得到保证 。
2. 提出了通过利用memory的类中心进行类中心指导的HEP Loss() , 从而可以捕获内部相似度和内部相似度以进行最终检索 。
在著名的面向图像级搜索的基准数据集上的大量实验表明 , 所提出的DC-I-Net优于最新的tasks-integrated和tasks-separated的图像搜索模型 。
二、本文方法

文章图片
这篇论文是I-Net的一个实质性扩展 , 在网络架构和损失函数方面做出了以下新贡献:
2.1 I-Net
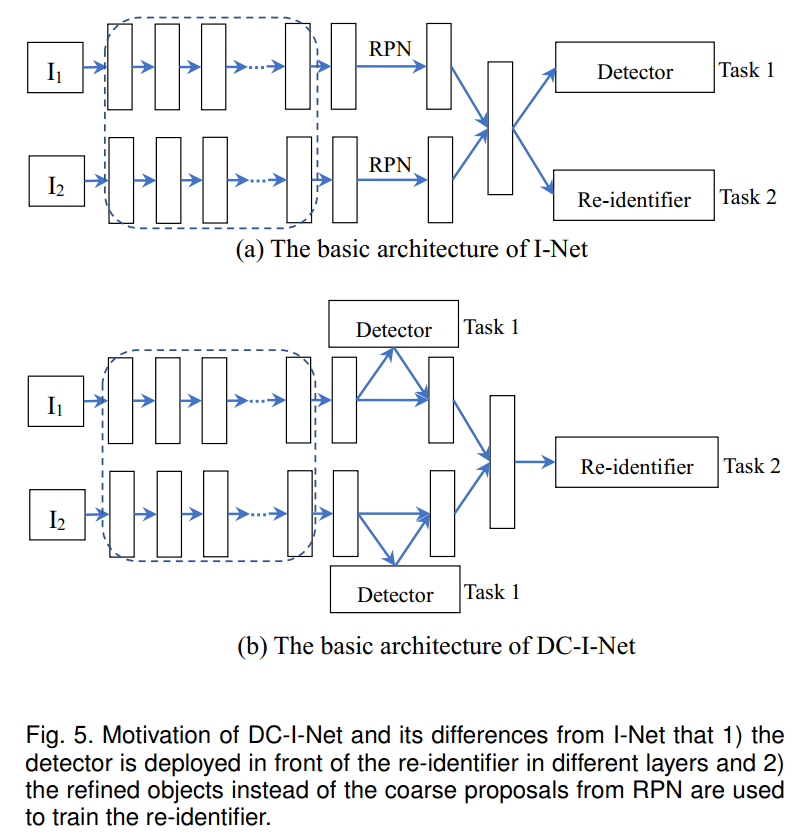
为了实现更好的图像搜索任务 , I-Net( Siamese I-Net) 将行人检测和行人重识别设计为端到端( End-to-End) 的框架 , 如下图:

文章图片
对于每一次迭代 , 包含相同身份id的图像对将被输入到Siamese I-Net中 。 利用骨干网络进行初步特征的提取 。 然后 , 通过两个RPN结构得到候选区域 。 再然后将这些候选区域特征输入到ROIPooling中并输出的特征图 , 最后是两个全连接层分别用于检测任务和检索检索 ( 即ReID) 任务 。 同时该结构的提出的同时也提出了两个损失函数 , 即OLP Loss和HEPLoss , 用于学习与ReID相关的有效特征 。
通过两个RPN生成的候选区域 , ROI池化层被集成到I-Net中 。 然后 , 两个Stream汇集的特征被输入到有4096个神经元的两个FC中 。 为了消除行人候选区域的假阳性使用二值交叉熵损失区分训练 。 ( 注意 , 对于一般的图像搜索任务都会使用softmax分类器来进行目标检测) ;除此之外L1损失用来约束候选框的位置 , 同时会有一对256-D的特征用通过OLP Loss和HEP Loss来训练ReID Branch的模型 。
2.2 On-line Pairing Loss ( OLP Loss)
设计OLP损失函数主要从以下几个角度考虑的:
1. 减小类内差距、增加类间差距
2. 由于输入的图像数量不足 , 且每幅图像中目标的锁定 , 容易出现容易对多而身份少的情况 , 会导致传统度量损失(如Triplet Loss)的停滞问题 , 严重阻碍了模型的有效训练 。
OLP Loss的设计形式如下:
OLP损失可以按照如下步骤进行复现:
1. 收集两幅相同身份输入图像的特性 , 并构造成正样本对 。
2. 为每个正样本对特征中的和被设置为Anchor 。 负样本特征存储在特征字典中 , 与Anchor对配对 , 构建负样本对 。
3. 计算OLP损失 , 然后计算OLP梯度 , 进行梯度反向传播优化 。
4. 存储输入的特征 , 逐步更新特征字典 。
2.3 Hard Example Priority Loss ( HEP Loss)
OLP损失函数使正样本对的余弦距离更小 , 负样本对的余弦距离更大 , 这并不能直接对损失函数中的id标签进行回归 。 另外 , 传统的基于softmax的分类器交叉损失训练方法没有考虑样本在数据中的难易程度 。 基于上述考虑 , 提出了HEP Loss , 目的是回归具有高优先级的身份标签 。
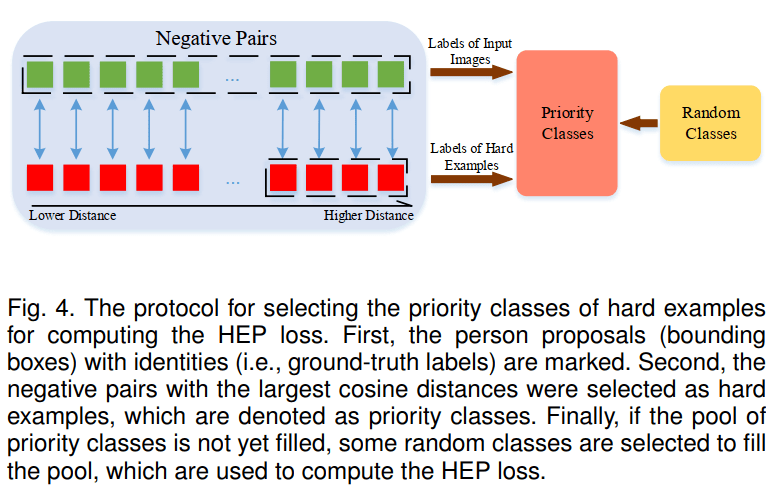
文章图片
在上图中 , Hard Example的选择如下:
1. 首先确定每个有身份的输入图像对的标签索引 , 以确保groundtruth类 。
2. 对于每个子组 , 将距离最大的最上面r个负样本的标签索引存储在优先级类池P中 , 使难例的优先级类得到集中 。
3. 如果池P的大小仍然小于预设的T , 便随机选择几个类填充池 。
最后 , 利用传统的基于softmax的交叉熵损失和选择的优先级类 , 将提出的HEP损失函数表示为:
其中 , 表示分类器给出的第i个proposal的分数 , j表示第j个类 。 在损失函数中 , 只使用选定的类别进行损失计算 , 进而使得损失函数集中在硬类别上 。
2.4 Overall Loss of I-Net
I-Net是一种将检测和重识别结合起来进行训练的端到端模型 。 因此损失由两部分组成:检测损失()和重识别损失(和) , 表示如下:
2.5 DC-I-NET
相较于I-Net , DC-I-NET:
2. 利用ROI-Align模块生成2级检测器来提取refined目标以用于训练度量损失;
3. 提出了class-center引导困难样本优先的()损失 , 用于训练的id的分类损失 。

文章图片
Re-identifier:经过两阶段检测后 , 将refined bounding Boxes的坐标输入ROIAlign层 , 计算refined目标建议的特征 , 用于行人重识别 。 对于ReID任务 , 汇集的feature map的大小为7x14 , 其宽高比与person的边框相似 。 然后将特征图输入全连通层 , 学习用于行人重识别的特征向量表示 。 最后 , 通过全连通层生成目标方案的256-D的经过L2归一化后特征 , 并将其输入到和中进行重识别模块的训练 。
损失函数定义如下:
文章图片
DC-I-Net总损失为:
三、实验结果

文章图片

文章图片

文章图片
更为详细内容可以参见论文中的描述 。
论文链接: https://arxiv.org/abs/2009.01438
【一身|干货! 集检测与检索与一身的模型,看得见也找得到】▼
推荐阅读







- 解决方案|【干货】反渗透设备结垢原因及解决方案
- IT|美律所对法拉第未来提起集体诉讼 涉嫌触犯证券法
- 系统验证|以技术革新加速芯片创新效率,EDA软件集成版PNDebug正式发布
- 集聚|向全球应用创新策源地持续迈进 上海“双千兆”应用体验中心正式揭牌
- 领域|上海市电子信息产业“十四五”规划:以集成电路为核心先导
- 平台|[原]蚂蚁集团SOFAStack:新一代分布式云PaaS平台,打造企业上云新体验
- IT|中国重汽:氢能源产品的核心布局和整车集成开发已经全面完成
- 影像|京东零售集团CEO辛利军空降小米“跑进2022”活动直播间为米粉送福利
- 携手同行|陕西华晨教育集团携手同行,共赢未来
- IT|中国首制,全球最大型集装箱船在沪出坞