
文章图片
作为最早的“装机必备”产品 , 讯飞输入法已经上线11周年 。
在移动互联网汹涌澎湃的十余年时间里 , 第三方输入法可以说是见证历史的史诗级产品:经历了智能手机普及初期的高速增长 , 经历了消费人群迭代的习惯变迁 , 经历了用户增长趋缓的多元探索 , 并且正在经历人工智能浪潮对输入法的新一轮重塑 。
有别于互联网的其他赛道 , 第三方输入法的市场格局可谓相当稳固 , 讯飞、搜狗、百度三足鼎立的局面已经持续了近十年的时间 , 期间也曾出现一些昙花一现的产品 , 但讯飞输入法在内的头部玩家 , 一次次用产品力验证了强大的用户忠诚度 。
对于个中隐藏的秘密 , 或许可以从进化到11.0版本的讯飞输入法身上找到答案:人工智能叙事逻辑下的输入法将朝什么样的方向进化 , 以及在应用场景、目标人群越来越细分的局面下 , 第三方输入法将解决哪些新诉求?这些亟待回答的新问题将直接左右第三方输入法的走向和格局 。
01 效率 , 输入法的主线任务 不同于单机时代到互联网时代的跃迁 , 人工智能大幕的拉开为第三方输入法提供了多种选择路径:比如不断丰富产品的可玩性 , 进一步占领用户时长摆脱工具型产品的定位;再比如加速进行横向延伸 , 抓住人机交互的入口优势不断进入新的赛道 , 继而在商业化方面有更多主动性……
讯飞输入法的回答却是效率 。
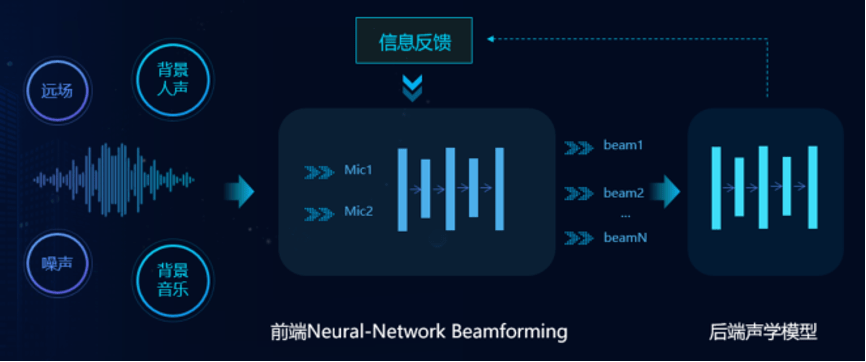
在讯飞输入法11.0的新功能中 , 最为耀眼的正是新一代语音识别框架TFMA , 解决了复杂场景下的语音识别问题 。 语音输入作为最典型的AI技术落地应用 , 最大的挑战非复杂场景莫属 , 因为用户的输入场景不可能是装有隔音墙的录音室 , 无处不在的噪声、混响直接影响着语音识别的准确率 , 进而左右用户的输入体验 。
为了解决语音识别在复杂环境下的普适性 , 科大讯飞的灵感源于著名的“鸡尾酒会”效应 , 即人耳在嘈杂的环境下可以巧妙地“离开”一段对话 , 去听一听旁边的人在说什么 , 属于典型的自上(大脑)而下(听觉系统)的机制 。 而传统的语音识别系统 , 往往是由麦克风阵列对音频做降噪处理 , 得到单路音频信号进行识别 , 遵循的是自下而上的机制 。
文章图片
科大讯飞由此提出了TFMA前后端一体化的方案 , 将语音识别的前后端联合优化 , 直接训练多通道信号的识别模型 , 然后将后端模型的隐层信息反馈到前端 , 指导前端基于神经网络的波束形成器更新 , 形成一套自下而上和自上而下结合的流程 , 同时引入大量的专家知识 , 融合神经网络和信号处理的优势 , 保证了系统的鲁棒性 。
推荐阅读


- 识别|沈阳地铁重大变化!能摘口罩吗?
- 识别|天津滨海机场RFID行李全流程跟踪系统完成建设 行李标签识别成功率可提升至99%
- 相关|科大讯飞:虚拟人交互平台1.0在媒体等行业已形成标准产品和应用
- 技术|探秘AI智慧之旅,科大讯飞AI学习机研学游第一期圆满落幕
- 识别率|一群年轻人教“AI”学手语,目标是让千万聋人被“听见”
- 信息|财报识别系统教你怎样做好金融信贷审批工作!
- 数据|车牌识别相机在无人值守称重行业的应用
- 通信技术|浙大最新研究“空气输入法”:空中动动手指就能给智能手表输入文本
- 识别|“刷手支付”来了?腾讯掌纹支付设备专利获授权
- 犯罪学|人脸识别有易破解隐患 准确定罪存在一定争议