当前 , 随着AI(人工智能)技术的日趋成熟和疫情的影响 , 整个社会加速进入以人工智能为代表的数字化新常态 。 AI应用已逐渐渗入到我们生产、生活的方方面面 , 并产生积极影响 。 比如 , AI在人脸识别、机器人客服、智能质检、辅助医疗、自动驾驶、风评风控等领域快速响应 , 提高了效率 。 在今年发布的国家“十四五“规划纲要中 , 人工智能更是被重点提及 , 已上升为国家战略高度 , 成为新一轮科技革命和产业变革的重要驱动力量 。
面对扑面而来的AI旋风 , 在Gartner2020年的一份调查中 , 超过85%的CIO表示将在两到三年内为企业部署AI(人工智能)和ML(机器学习) 。
在人工智能发展的三个要素数据、算力和算法中 , 数据和算力主要受限于信息基础设施的建设 。 随着AI/ML在各行各业中多点开花 , 数据作为关键生产要素的作用愈发突出 , 海量数据的采集、存储、访问和应用让存储层挑战越来越大 。
AI 时代 , 计算之外的存储架构挑战
AI 时代 , 算力是产业发展的推力 , 要保证 AI 应用的持续高效运行 , 承载数据的存储系统也必须跟上时代的步伐 。 如何在有限资源投入下 , 充分发挥算法算力优势 , 最大限度地推动AI应用落地和释放数据价值 , 已经成为信息基础设施运营者们迫切需要解决的问题 。 其挑战主要体现在以下几个方面:
1.如何接入和保存各类来源、各种格式的数据 , 真正做到“海纳百川”?
在大量的AI场景之中 , 海量非结构化数据(图片、视频、音频、文档等)占据主流 , 单个文件通常很小 , 一般大小仅为几KB或几百KB , 但文件数量极大 。 例如在金融领域 , 金融业务不仅产生大量原始票据扫描件 , 还有电子合同、签名数据、人脸识别数据等 , 数量甚至可以高达数十亿级规模;在自动驾驶领域 , 单个数据集可能就包含10万+数量的视频、图片及相应标准 , 近年来又增加了许多雷达数据 , 总数据量往往达到几百TB甚至数PB , 这对于存储的吞吐量、延迟要求极高 。
在大多数企业中 , 数据通常以业务线为单位组织和管理 , 并且多数情况下 , 使用的是不同的中间件技术 。 随着云计算特别是容器技术的不断发展 , 大量基于物理机和虚拟机等传统IT架构的应用被迁移到云平台上 , IT架构不断演变 。 如何有效整合新型IT架构与现有存储设备成为难题 。
2.机器学习开发 , 如何满足各阶段对数据的存储和管理要求?
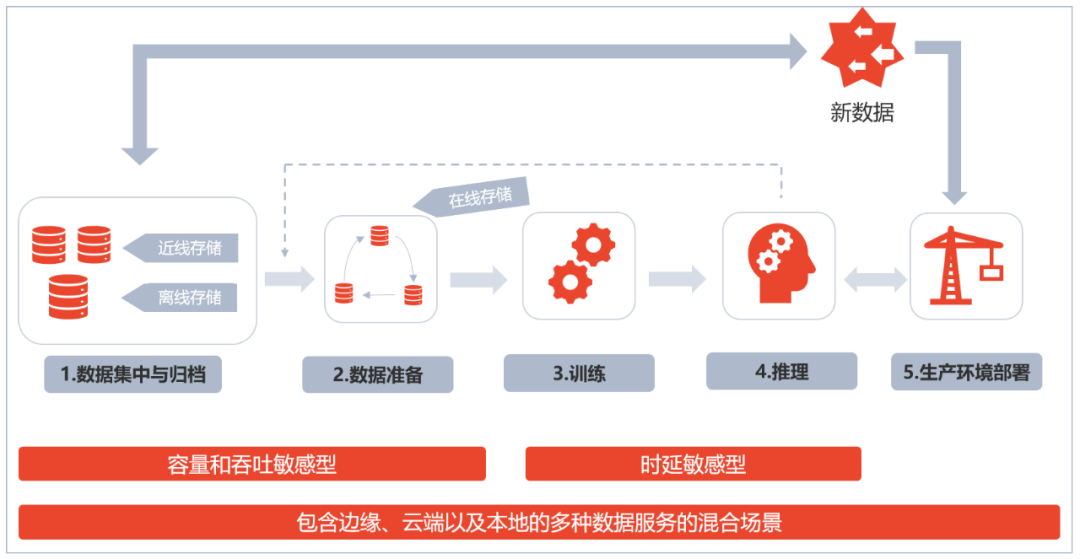
如下图所示 , 机器学习开发大致分为4个大的阶段:数据集中与归档、数据准备、模型训练、推理 。 不同阶段对底层存储的要求不同 。
推荐阅读





- 代码|GGV纪源资本连投三轮,这家无代码公司想让运营流程变简单
- 智能化|适老化服务让银行更有温度
- bug|这款小工具让你的Win10用上“Win11亚克力半透明菜单”
- 软件和应用|AcrylicMenus:让Windows 10右键菜单获得半透明效果
- ASUS|ROG Maximus Z690 APEX DDR5主板实测 转接卡让DDR4内存顺利点亮
- 识别|沈阳地铁重大变化!能摘口罩吗?
- 识别|天津滨海机场RFID行李全流程跟踪系统完成建设 行李标签识别成功率可提升至99%
- 视点·观察|张庭夫妇公司被查 该怎样精准鉴别网络传销?
- 泡芙|传下去
- 电子商务|员工抱怨亚马逊太冷酷:工伤后得不到赔偿 还不让休假