user_id|滴滴 x StarRocks:极速多维分析创造更大的业务价值
滴滴集团作为生活服务领域的头部企业 , 正在全面测试和上线StarRocks 。 其中橙心优选经过一年多的数据体系建设 , 我们逐渐将一部分需要实时交互查询、即席查询的多维数据分析需求由ClickHouse迁移到了StarRocks中 , StarRocks在稳定性、实时性方面也给了我们良好的体验 , 接下来以StarRocks实现的漏斗分析为例介绍StarRocks在橙心优选运营数据分析应用中的实践 。
作者:王鹏 滴滴橙心优选数据架构部资深数据架构开发工程师 , 负责橙心优选大数据基础服务和数据应用的开发与建设
需求介绍
当前我们数据门户上的漏斗分析看板分散 , 每个看板通常只能支持一个场景的漏斗分析 , 不利于用户统一看数或横向对比等 , 看板无法支持自选漏斗步骤、下钻拆解等灵活分析的功能 。 因此 , 我们需要一款能覆盖更全的流量数据 , 支持灵活筛选维度、灵活选择漏斗 , 提供多种分析视角的漏斗分析工具 , 并定位流失人群、转化人群 , 从而缩小问题范围 , 精准找到运营策略、产品设计优化点 , 实现精细化运营 。
技术选型
电商场景的流量日志、行为日志一般会比传统场景下的数据量大很多 , 因此在这样的背景下做漏斗分析给我们带来了两大技术挑战:
·日增数据量大:日增千万级数据 , 支持灵活选择维度 , 如何快速地对亿级数据量进行多维分析
·对数据分析时效性要求高:如何快速地基于亿级数据量精确去重 , 获取符合条件的用户数量
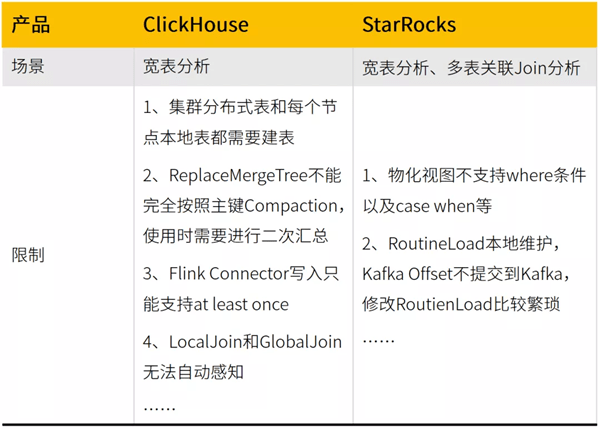
StarRocks与ClickHouse在橙心内部都有广泛的应用 , 我们也积累了丰富的经验 , 但StarRocks在易用性和可维护性上都比ClickHouse更胜一筹 , 下面这张表格是我们在使用过程中对两者功能的一个简单对比:
文章图片
经过不断地对比和压测 , 我们最终决定使用StarRocks来存储需要进行漏斗分析的数据 , 因为StarRocks在SQL监控、运维方面相比ClickHouse的优势明显 , 而且我们可以为了满足不同的查询场景 , 基于漏斗分析明细表创建各种各样的物化视图 , 提高多维数据分析的速度 。
系统架构

文章图片
系统各层职责说明如下:
1、数据源:主要是web端、客户端的埋点日志 , 这些埋点日志源源不断地上传给我们的数据接入层
2、数据接入层:
(1)数据接入总线:提供多种数据源的接入接口 , 接收并校验数据 , 对应用层屏蔽复杂的数据格式 , 对埋点日志进行校验和简单地清洗、转换后 , 将日志数据推送到Kafka集群
(2)Kafka集群:数据接入总线与数据计算集群的中间层 。 数据接入总线的对应接口将数据接收并校验完成后 , 将数据统一推送给Kafka集群 。 Kafka集群解耦了数据接入总线和数据计算集群 , 利用Kafka自身的能力 , 实现流量控制 , 释放高峰时日志数据量过大对下游计算集群、存储系统造成的压力
推荐阅读


- 警告!|华为联想卷入滴滴高管千万受贿案 判决书曝光浪潮曾向其输送720多万
- IT|滴滴被“围剿”三个月:Q3经调整EBITA由盈转亏 订单量、交易额均下滑
- IT|滴滴三季度收入427亿元环比降13%,投资亏损208亿元
- 注销|中消协点名推荐退订"问题" APP 含曹操出行翼支付滴滴
- join|ClickHouse vs StarRocks选型对比
- 视点·观察|仅156天!滴滴股价腰斩,再赴港上市之路怎么走?
- the|美股周五:特斯拉跌逾6% 滴滴大跌超22%
- 视点·观察|美股退市上港股 滴滴还有劲折腾么?
- IT|投资者割肉止损 滴滴股价跌超22%
- app|滴滴旗下滴滴加油、DiDi-Rider恢复上架?两款App并未下架过