硬件|存内计算,走在爆发的边缘
怎样才能让一枚芯片拥有更高的性能?大多数人的回答一定是紧跟摩尔定律 , 在同样大小的芯片空间内装进更多的晶体管 , 其手段无外乎更先进的制程(从7nm到5nm)以及更先进的封装方式(如chiplet) 。
作者|洪雨晗
然而 , 随着先进制程逼近1nm的物理极限 , 摩尔定律不可避免的放缓 , 即便是在日常生活中 , 人们也能感受到手机Soc、电脑的CPU的升级换代效果越来越差 , 从过去的每代提升40%性能迅速下降至20%甚至10% 。
与之对应的是 , 当今社会对数据、算力、芯片性能的要求却越来越高 , 整个下游市场既然有庞大的需求出现 , 那么整个产业链的各方都在想方设法来提高芯片的性能 , 既然传统的在晶圆上改进工艺的方式进展缓慢 , 那么在更上层的计算机架构上动刀或许会有意想不到的收获 。
今年以来 , 一些跳出传统计算机结构体系的设想正在转为研究成果出现在各大顶级期刊上 , 它就是“存内计算” 。
存内计算 , 顾名思义就是把计算单元嵌入到内存当中 。通常计算机运行的冯·诺依曼体系包括存储单元和计算单元两部分 , 计算机实施运算需要先把数据存入主存储器 , 再按顺序从主存储器中取出指令 , 一条一条的执行 , 数据需要在处理器与存储器之间进行频繁迁移 , 如果内存的传输速度跟不上CPU的性能 , 就会导致计算能力受到限制 , 即“内存墙”出现 , 例如 , CPU处理运算一道指令的耗时假若为1ns , 但内存读取传输该指令的耗时可能就已达到10ns , 严重影响了CPU的运行处理速度 。
此外 , 读写一次内存的数据能量比计算一次数据的能量多消耗几百倍 , 也就是“功耗墙”的存在 。2018年 , Google针对自家产品(Chome/Tensorflow Mobile/video playback/video capture)的耗能情况做了一项研究 , 发现整个系统耗能的62.7%浪费在CPU和内存的读写传输上 , 传统冯·诺依曼架构导致的高延迟和高耗能的问题成为急需解决的问题 , 其中的短板存储器成为了制约数据处理速度提高的主要瓶颈 。
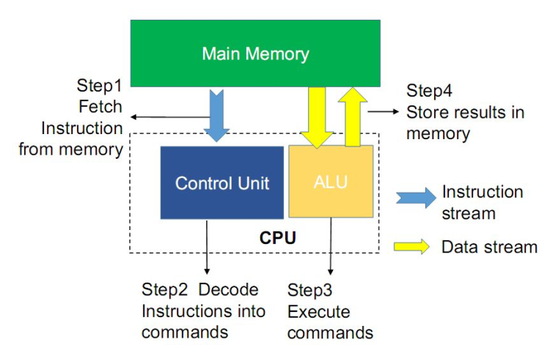
文章图片
冯·诺依曼架构图
把计算单元嵌入到内存当中的理想情况下 , 存内计算可以有效消除存储单元与计算单元之间的数据传输耗能过高、速度有限的情况 , 从而有效解决冯诺依曼瓶颈 。
存内计算的概念早就有迹可循 , 在上世纪70年代William H 。Kautz就曾提出过存储和逻辑整合的方案 , Harold S 。Stone紧接着发表了支持逻辑运算的存储计算结构 , 但由于当时的性能瓶颈问题不算突出 , 处理器的发展暂能满足数据处理的需求 , 因而学界、业界并没有对该领域投入过多关注 。
【硬件|存内计算,走在爆发的边缘】如今 , 随着人工智能技术的发展 , AI在各领域的应用逐渐广泛 , 以深度学习为代表的神经网络算法需要系统能高效处理海量的非结构化数据 , 例如文本、视频、图像、语音等 , 这导致在冯·诺伊曼架构下的硬件需要频繁读写内存 , 其计算任务有着并行运算量大、参数多的特点 , 这使得AI芯片对并行运算、低延迟、带宽等有着更高的要求 , 也因此 , 存内计算在人工智能时代迎来了发展的黄金时期 。
存内计算的热度肉眼可见的在各大学术会议上发酵 。2018年的IEEE国际固态电路会议(ISSCC)专门用了一个议程来研讨存内计算相关话题;到2019年 , 电子器件领域的顶级会议IEDM上关于存内计算的研讨议程则变成了三个 , 相关论文也达到二十余篇;2020年的ISSCC上存内计算的论文也上升至七篇 。
存内计算不只是学界的圈地自娱 , 三星、SK海力士、台积电、英特尔、美光、IBM等半导体领域的巨头也在加紧对该技术的研发 , 今年的竞争更是尤为激烈 , 首先三星在顶级学术期刊Nature上发表了全球首个基于MRAM(磁性随机存储器)的存内计算研究 , 紧接着台积电在近日的ISSCC上合作发表了六篇关于存内计算存储器IP的论文 , 大力推进基于ReRAM的存内计算方案 , SK海力士则发表了基于GDDR接口的DRAM存内计算研究 。
应着这阵风口 , 我国的存内计算产业也开始迅猛发展 , 知存科技、九天睿芯、智芯科、后摩智能、苹芯科技等国内专注存内计算赛道的新兴公司纷纷获得融资 , 加速在该领域的早期市场布局及商业落地 。
虽然不管学界、业界还是市场对存内计算的呼声都极高 , 相关研究和产品的研发在如火如荼的进行 , 但在现阶段存内计算的实现确实面临着诸多难点 , 目前市面上仍缺乏被市场认可而广泛应用的存内计算产品出现 。
目前 , 业界实现存内计算的三种主流路径为SRAM、DRAM、Flash , 简单来说DRAM内存具有动态刷新 , 断电会丢失数据的特征 , SRAM为高速缓存 , 其无需刷新 , 但同样会在断电状态下丢失数据 , Flash则为闪存 , 其有着无需刷新 , 断电不丢数据的特征 , 通常作为硬盘使用 。
选择SRAM路径的代表性半导体企业为台积电 , 它可以在5nm的先进工艺上制造 。SRAM的存储逻辑简单清晰 , 和现在的数字处理器技术更容易结合 , 同时 , SRAM离CPU近读写性能优势较大 , 但作为易失性存储器的SRAM同时也有着断电后数据无法保存的问题 , 因此SRAM还需要在断电后把数据传输到其它存储器中 。
Flash阵营的代表玩家为美国的Mythic公司 , Flash是一种业内较为成熟的存储器技术 , 它在功能工艺参数、器件模型上都有着成熟的工具 , 同时 , 其系统架构的核心设计可以向非易失性的RRAM(电阻式随机存取存储器)等新型非挥发器件上迁移 , 迅速完成产品的更新迭代 ,
基于DRAM的存内计算芯片 , 目前采用该方案的公司较少 , 因为其技术落地的时间暂不明朗 。DRAM存内计算适合大算力AI芯片 , 其对硬件的通用性和可编程性的要求更高 , 这对目前专用性的架构来说需要花更多心思来重新设计 , 其难度自然更高 。
综合来看 , 存内计算的实现基于相对成熟的易失性存储和不太成熟的非易失性存储 , 但无论是哪种路线的实现都存在一定的挑战 , 几大技术方向也都在发展中 。易失性存储路线在融合处理器工艺和存储器工艺上存在诸多难题 , 在冯·诺依曼架构下 , 处理器与存储器的区隔明显 , 从设计、制造、封装全流程 , 它们各自都发展出了独立的生态 , 想要把两者融合成一体 , 其工艺难度可想而知 。知存科技走的就是易失性存储路线 , 其CEO王绍迪曾形容过该路线早期开发的难度:“早期研发的时候 , 由于缺乏晶圆工厂和EDA工具的支持 , 我们的开发工作很多就要从自动变成手动 。”非易失性存储对存储目前厂商和工艺也均未成熟 。
极强的市场需求与暂未明朗的技术产品 , 谁能率先在可控的成本内实现存内计算存储密度与计算密度的平衡 , 谁或许就摸索到了成为下一个英伟达的路径 。
访问:
京东商城
推荐阅读







- 硬件|旺季不旺 创新乏力 手机市场遭遇“倒春寒”
- 硬件|遭纽约警察局解聘后 波士顿动力机器狗又被消防局返聘
- 硬件|4.98万起!大疆经纬M30系列无人机发布:热成像、激光测距全都有
- Windows|Windows 11在不支持的硬件环境中打上新的桌面水印
- 硬件|涨价三年的显卡崩盘在即 有迹象显示厂商即将降价
- 硬件|显示器常见背光种类盘点 蓝光最强的它竟然应用最广?
- 硬件|前NASA工程师让钢琴开口说英文 还能自弹世界上最难曲目 快到冒烟
- 中东|纽约大学分校将举办中东地区首届量子计算编程马拉松
- 硬件|GPU上集成CPU内核 AMD显卡部门招聘RISC-V设计师
- 硬件|零售商列表显示RX 6500 XT在德国比官价还便宜35%