选自gradient
作者:Walid S. Saba
机器之心编译
编辑:陈萍
自然语言理解(NLU)是人工智能的核心课题之一 , 也被广泛认为是最困难和最具标志性的任务 。 近年来 , 机器学习虽然被广泛使用 , 但是却不能很好的解决自然语言理解问题 , 其中可能涉及很多原因 , ONTOLOGIK.AI 的创始人和首席NLU科学家Walid Saba给出了自己的观点 。

文章图片
20 世纪 90 年代早期 , 一场统计学革命取代了人工智能 , 并在 2000 年达到顶峰 , 而神经网络凭借深度学习成功回归 。 这一经验主义转变吞噬了人工智能的所有子领域 , 其中这项技术最具争议的应用领域是自然语言处理 。
以数据为驱动的经验方法在 NLP 中被广泛使用的原因主要包括:符号和逻辑方法在取得三十年的霸权后未能产生可扩展的 NLP 系统 , 从而导致 NLP 中所谓的经验方法(EMNLP)兴起 , 这些方法可以用数据驱动、基于语料库、统计和机器学习来统称 。
这种向经验主义转变的背后动机非常简单:在我们对语言是如何工作、以及语言如何与日常口语中谈论的世界知识相关联的 , 在对这些了解之前 , 经验和数据驱动的方法有助于构建文本处理应用程序 。 正如 EMNLP 的先驱之一 Kenneth Church 所解释的那样 , 在 NLP 领域 , 倡导数据驱动和统计方法的科研人员 , 他们对解决简单的语言任务感兴趣 , 其动机从来不是暗示语言就是这样工作的 , 而是做简单的事情总比什么都不做要好 。 Church 认为这种转变动机被严重误解了 , 正如 McShane 在 2017 年所指出的 , 后来的几代人误解了这种经验趋势 。

文章图片
EMNLP 会议创立者、先驱之一 Kenneth Church 。
这种被误导的趋势导致了一种不幸的情况:坚持使用大型语言模型(large language model, LLM)构建 NLP 系统 , 这需要巨大的计算能力 , 而且试图通过记忆大量数据来接近自然语言对象 , 这种做法是徒劳的 。 这种伪科学的方法不仅浪费时间和资源 , 而且会误导新一代的年轻科学家 , 错误地让他们认为语言就是数据 。 更糟糕的是 , 这种做法还阻碍了自然语言理解(NLU)的发展 。
相反 , 现在应该重新思考 NLU 方法 , 因为对于 NLU 来说 , 大数据方法不但在心理上、认知上 , 甚至计算上都让人难以置信 , 而且盲目数据驱动的方法在理论上和技术上也是有缺陷的 。
自然语言处理 VS 自然语言理解
虽然自然语言处理(NLP)和自然语言理解(NLU)经常互换使用 , 但是两者之间存在实质性差异 , 突出这种差异至关重要 。 事实上 , 区分自然语言处理和自然语言理解之间的技术差异 , 我们可以意识到以数据驱动和机器学习的方法虽然适用于 NLP 任务 , 但这种方法与 NLU 无关 。 以 NLP 中最常见的下游任务为例:
- 摘要;
- 主题抽取;
- 命名实体识别;
- 语义检索;
- 自动标签;
- 聚类 。
我们是否有一位退休的 BBC 采访人员在冷战期间驻扎在东欧国家?在数据库中 , 对上述查询将有且只有一个正确答案 。 将上述表达转化为正确的 SQL 或者 SPARQL 查询具有很大的挑战性 。 这个问题背后的关键点包括:
- 需要正确解读「退休的 BBC 采访人员」 , 即所有曾在 BBC 工作、现已退休的采访人员的集合;
- 通过保留那些曾经也在一些「东欧国家」工作过的「退休 BBC 采访人员」来进一步过滤上述内容 。 除了地理限制 , 还有时间限制 , 那些「退休的 BBC 采访人员」的工作时间必须是「冷战期间」;
- 以上意味着将介词短语「在冷战期间」附加到「驻扎」而不是「东欧国家」;
- 进行正确的量词范围界定:我们寻找的不是在某个东欧国家工作的一个(单一)采访人员 , 而是在任何东欧国家工作的任何采访人员 。
通过这个简短的描述 , 我们应该可以清楚地了解为什么 NLP 与 NLU 不同 , 以及为什么 NLU 对机器来说是困难的 。 但是 NLU 的困难到底是什么呢?
NLU 难点在于缺失文本现象
所谓的缺失文本现象(missing text phenomenon, MTP) , 可以将其理解为 NLP 任务挑战的核心 。 语言交流的过程如下图所示:说者将思想编码为某种语言表达 , 然后听者将该语言表达解码为说者意图传达的思想 。
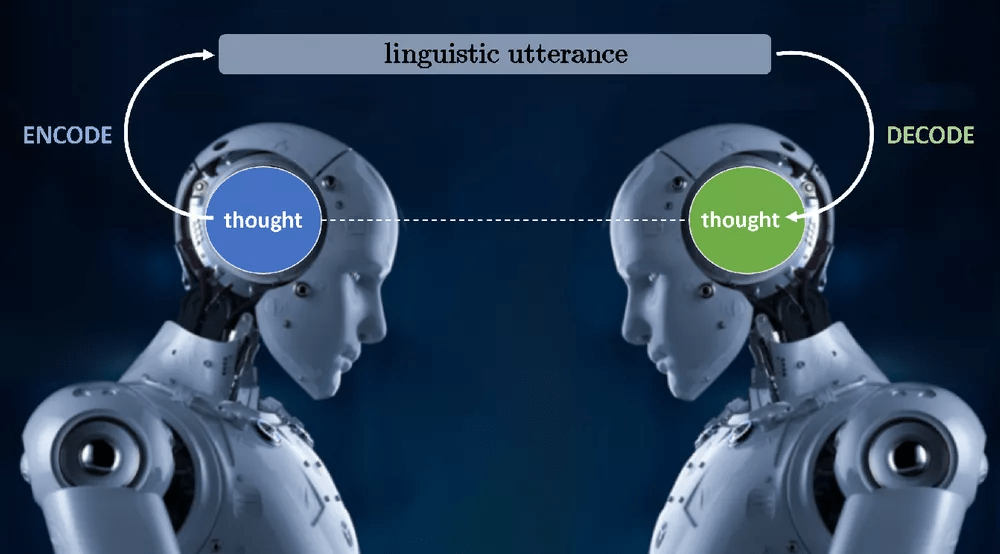
文章图片
图 1:说者和听者的语言交流过程 。
解码过程就是 NLU 中的 U——也就是说 , 理解语言话语背后的思想正是解码过程需要做的事情 。 此外 , 在这个解码过程中没有近似或任何自由度——也就是说 , 从一个话语的多种可能意义来看 , 说话人想要表达的思想只有一个 , 而解码过程中的「理解」必须达到这一个思想 , 这正是 NLU 困难的原因 。
在这种复杂的交流中 , 有两种可能的优化方案:(1)说者可以压缩(和最小化)在编码中发送的信息量 , 并希望听者在解码(解压缩)过程中做一些额外的工作;(2)说者尽最大努力传递所有必要的信息来传达思想 , 而听者几乎什么也不用做 。
随着过程的自然演变 , 上述两种方案似乎已经得到一个很好的平衡 , 即说者和听者的总体工作都得到了同样的优化 。 这种优化导致说者可以编码尽可能少的信息 , 而忽略其他信息 。 遗漏的信息对于说者和听者来说 , 是可以通过安全假设获得的信息 , 这正是我们经常说的普通背景知识 。
为了理解这一过程的复杂性 , 以下图为例:黄色框中的是未优化的信息 , 以及我们通常所说的信息量同等但小得多的文本信息(绿色框中信息) 。
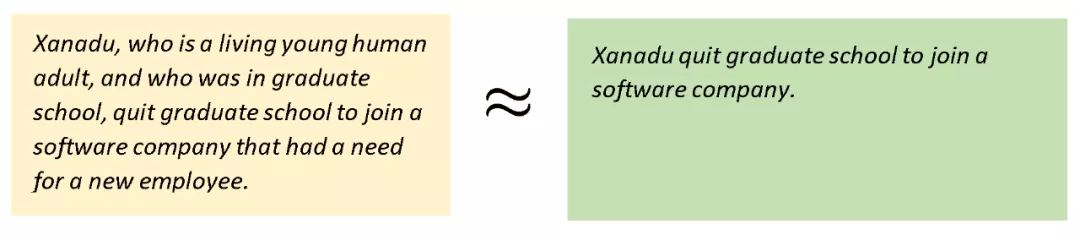
文章图片
绿色框中信息要短很多 , 这正是我们说话的方式 , 语言虽短 , 但传达的是与较长信息相同的思想 。 通常我们不会明确地说出所有想要表达的东西:

文章图片
也就是说 , 为了有效地沟通 , 我们在交流中通常不会说认为对方说都知道的信息 。 这也正是为什么我们都倾向于忽略相同的信息——因为我们都了解每个人都知道的 , 而这正是我们所谓的共同背景知识 。 人类在大约 20 万年的进化过程中 , 发展出的这一天才优化过程非常有效 。 但这就是 NLU 的问题所在:机器不知道我们遗漏了什么信息 , 因为机器不知道我们都知道什么 。 最终结果导致 NLU 是非常困难的 , 因为如果一个软件程序不能以某种方式揭示人类在语言交流中遗漏和隐含的所有东西 , 它就不能完全理解我们语言话语背后的思想 。 这实际上才是 NLU 的挑战 , 而不是解析、词干分析、词性标记、命名实体识别等 。

文章图片
图 2:NLU 中很多挑战都是因为缺失文本现象造成的:图中缺失的文本(隐式的假设)用红色表示 。
上述示例表明 , NLU 的挑战在于发现缺失信息 , 并隐含地认为这些信息是共享背景知识 。 下图 3 进一步解释了缺失文本现象:

文章图片
我们在下文给出三个原因来解释为什么机器学习和数据驱动方法不能解决 NLU 问题 。
ML 方法与 NLU 无关:ML 是压缩 , 语言理解需要解压缩
用机器来实现自然语言理解是非常困难的 , 因为我们日常口语所表达的都是高度压缩信息 , 「理解」的挑战在于解压缩出丢失文本 。 这对人类来说是很简单的事情 , 但对机器来说却大不相同 , 因为机器不知道人类掌握的知识 。 但 MTP 现象恰恰说明了为什么数据驱动与机器学习方法会在 NLP 任务中有效 , 但是在 NLU 中不起作用 。
研究者在数学上已经建立了可学习性和可压缩性(COMP)之间的等价关系 。 也就是说 , 只有当数据高度可压缩(即它有很多冗余)时 , 在数据集中才会发生可学习性 , 反之亦然 。 虽然证明可压缩性和可学习性之间的关系相当复杂 , 但直观上很容易理解:可学习性是关于理解大数据的 , 它在多维空间中找到一个函数可以覆盖所有的数据集信息 。 因此 , 当所有数据点都可以压缩成一个流形时 , 就会发生可学习性 。 但是 MTP 告诉我们 NLU 是关于解压缩的 。 以下列内容为例:

文章图片
机器学习是将大量数据泛化为单个函数 。 另一方面 , 由于 MTP , 自然语言理解需要智能的解压缩技术 , 以发现所有缺失和隐式假设文本 。 因此 , 机器学习和语言理解是不相容的——事实上 , 它们是矛盾的 。
ML 方法甚至与 NLU 无关:统计意义不大
ML 本质上是一种基于数据发现某些模式(相关性)的范式 。 研究者希望在自然语言中出现的各种现象在统计上存在显著差异 。 举例来说:
1. 奖杯装不进手提箱 , 因为它太
1a. 小
1b. 大同义词与反义词(例如小和大 , 开和关等)以相同的概率出现在上下文中 , 因此 , 在统计上来说 (1a) 和(1b) 是等价的 , 然而 (1a) 和(1b)所代表的内容也是相当不同的:在此句中 , 「它」在 (1a)中隐含的意思是指手提箱小 , 但在 (1b) 中是指奖杯大 , 尽管它们的语义相差很大 , 但是 (1a) 和(1b)在统计上是等价的 。 因此 , 统计分析不能建模(甚至不能近似)语义 。
ML 方法甚至与 NLU 无关:intenSion
逻辑学家长期以来一直在研究一种称为「intension」的语义概念 。 为了解释什么是「intension」 , 首先要从所谓的语义三角(meaning triangle)开始讲起 , 如下图所示:
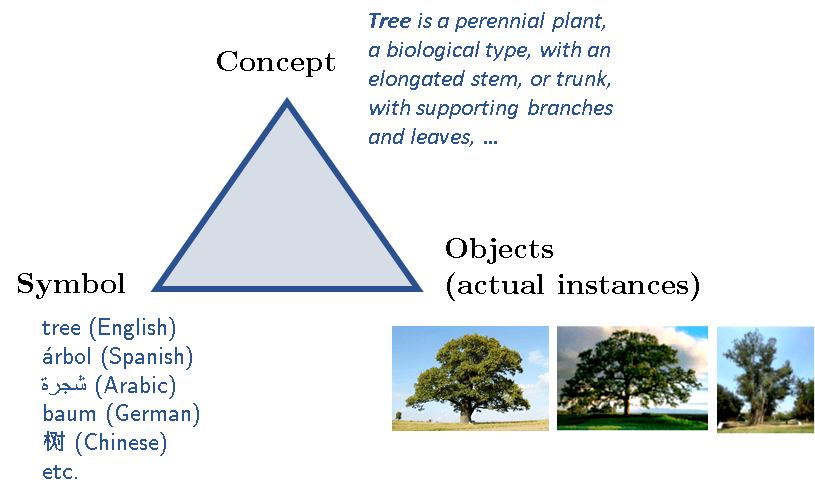
文章图片
在语义三角中 , 每个「事物(或每个认知对象)」都具有三部分:一个指代概念符号 , 以及这个概念(有时)具有的一些实例 。 以「独角兽」这个概念为例 , 在现实生活中并没有实际的示例 。 概念本身是其所有潜在实例的理想化模板 , 可以想象 , 几个世纪以来 , 哲学家、逻辑学家和认知科学家一直在争论概念的本质及其定义 , 不管那场辩论如何 , 我们可以在一件事情上达成一致:一个概念(通常由某个符号 / 标签引用)由一组特性集合和属性定义 , 也许还有附加公理和既定事实等 。 然而 , 一个概念与实际(不完美)实例不同 , 在完美的数学世界中也是如此 。 举例而言 , 虽然下面的算术表达式都具有相同的扩展 , 但它们具有不同的「intension」:
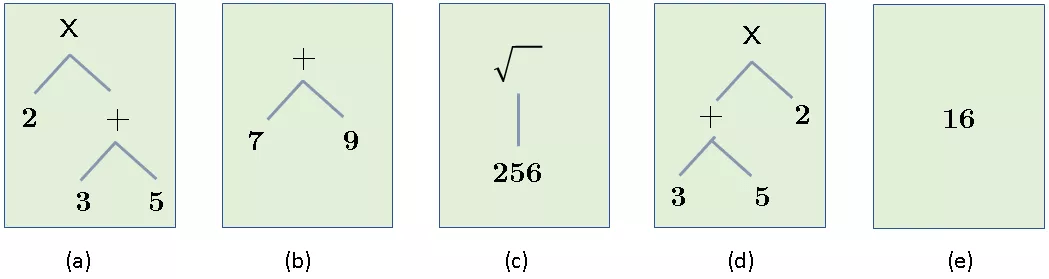
文章图片
上图中所有表达式的值都是 16 , 在某种意义(它们的值)上来说是相等的 , 但这只是属性之一 。 事实上 , 上面的表达式还有其他几个属性 , 比如语法结构(为什么 a 和 d 是不同的)、运算符的数量等 。 其中值只是一个属性 , 可以称为扩展(extension) , 而所有属性的集合是 intension 。 在应用科学(工程、经济学等)中 , 我们可以认为这些对象是相等的 , 如果它们在值上是相等的 , 但在认知中 , 这种相等是不存在的 。 举例来说:
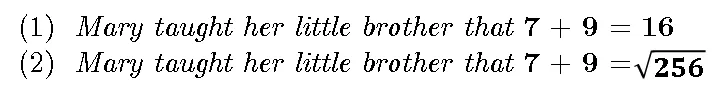
文章图片
假设 (1) 是真的——也就是说 , 假设 (1) 确实发生了 , 并且我们见证了它 。 尽管如此 , 这并不意味着我们可以假设 (2) 为真 , 尽管我们所做的只是将 (1) 中的 16 替换为一个(假设) , 而该假设等于它的值 。 我们用一个假定等于它的对象替换了陈述中的一个对象 , 并且我们从真实的事物推断出不真实的事物!虽然在物理科学中可以很容易地用一个属性的对象来替换它 , 但这在认知中是行不通的 。
总结来说 , 本文讨论了机器学习和数据驱动方法与 NLU 无关的三个原因(尽管这些方法可能用于一些本质上是压缩任务的文本处理任务) 。 在传达思想时 , 我们传递的是高度压缩的语言信息 , 需要大脑来解释和揭示所有缺失但隐含的背景信息 。 在很多方面 , 构建大语言模型时 , 机器学习和数据驱动方法都在徒劳地试图寻找数据中根本不存在的东西 。 我们必须意识到 , 日常的口语信息 , 并不是理想的语言数据 。
原文链接:https://thegradient.pub/machine-learning-wont-solve-the-natural-language-understanding-challenge/
推荐阅读





- Linux|Fedora 36默认字体将改为Noto,以覆盖更多语言
- 人物|日本高中生开发创意“语言计算器”获大奖 突破1+1=2模式
- 语法|?沈家煊《从语言看中西方的范畴观》
- 功能|谷歌正开发Panlingual功能:Android 13支持为单个App指定语言
- Google|Android 13正开发Panlingual功能:可为单个App指定语言
- Google|Android 13正开发Panlingual功能:为APP指定语言
- 模式|考那么多试,拿那么高分,大模型们真的懂语言了吗?
- 网络|为什么要拒绝低俗网络用语
- 研究成果|本世纪末1500种语言或不再使用
- 语言|本世纪末1500种语言或不再使用