模型|在CUDA的天下,OpenAI开源GPU编程语言Triton,将同时支持N卡和A卡
机器之心报道
编辑:蛋酱、陈萍
OpenAI 开源了全新的 GPU 编程语言 Triton , 它能成为 CUDA 的替代品吗?过去十年中 , 深度神经网络 (DNN) 已成为最重要的机器学习模型之一 , 创造了从自然语言处理到计算机视觉、计算神经科学等许多领域的 SOTA 实现 。 DNN 模型的优势来自于它的层次结构 , 这一特征导致其计算量巨大 , 但也会产生大量高度并行化的工作 , 特别适合多核和众核处理器 。
深度学习领域的新研究思路往往是结合原生框架 operator 来实现的 , 这种方法虽然方便 , 但需要创建或移动许多临时张量 , 因此可能会造成神经网络的性能损失 。 编写专门的 GPU 内核或许可以解决这个问题 , 但 GPU 编程的确是一件相当复杂的事 。
DNN 计算潜力与 GPU 编程困难之间的矛盾由来已久 。 英伟达在 2007 年发布了 CUDA 的初始版本 , CUDA 平台是一个软件层 , 使用者可以直接访问 GPU 的虚拟指令集和并行计算单元 , 用于执行计算内核 。 近年来 , 主流深度学习框架几乎都是基于 CUDA 进行加速 , 英伟达也一直在完善 CUDA 工具包 , 但对于一般的开发者来说 , CUDA 还是「不那么容易上手」 。
文章图片
今天 , OpenAI 正式推出 Triton 1.0 , 这是一种类 Python 的开源编程语言 。 即使没有 CUDA 经验的研究人员 , 也能够高效编写 GPU 代码 。 例如 , 它可以用不到 25 行代码写出与 cuBLAS 性能相匹配的 FP16 矩阵乘法内核 , 后者是许多专业的 GPU 编程者尚且无法做到的 。 此外 , OpenAI 的研究者已经使用 Triton 成功生成了比 PyTorch 同类实现效率高 2 倍的内核 。
代码地址:https://github.com/openai/triton
Triton 的最初想法来源于现任 OpenAI 科学家的 Philippe Tillet 2019 年在哈佛大学攻读研究生学位时发表的一篇论文 , 当时他的导师是 H. T. Kung 和 David Cox 。

文章图片
论文链接:http://www.eecs.harvard.edu/~htk/publication/2019-mapl-tillet-kung-cox.pdf
Tillet 希望解决的问题是打造一种比英伟达的 CUDA 等特定供应商库更好用的库 , 能够处理神经网络中涉及矩阵的各种操作 , 具备可移植性 , 且性能可与 cuDNN 或类似的供应商库相媲美 。 团队表示:「直接用 CUDA 进行 GPU 编程太难了 , 比如为 GPU 编写原生内核或函数这件事 , 会因为 GPU 编程的复杂性而出奇困难 。 」
Facebook AI 研究中心科学家 Soumith Chintala 也在推特上表达了自己对 Triton 的期待:
文章图片
新发布的 Triton 可以为一些核心的神经网络任务(例如矩阵乘法)提供显著的易用性优势 。 「我们的目标是使其成为深度学习 CUDA 的可行替代方案 , 」Philippe Tillet 作为 Triton 项目负责人如此表示 。
GPU 编程面临的挑战
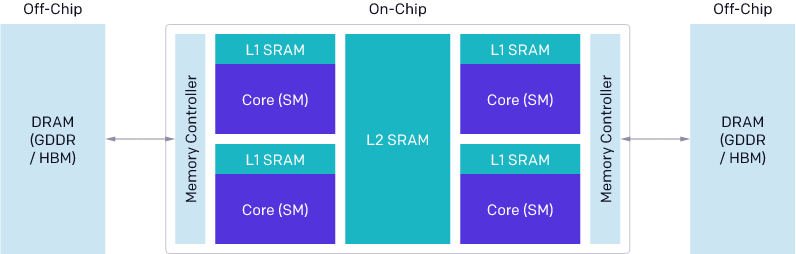
现代 GPU 的架构大致可以分为三个主要组件:DRAM、SRAM 和 ALU 。 优化 CUDA 代码时 , 必须考虑到每一个组件:
- 来自 DRAM 的内存传输必须合并进大型事务 , 以利用现代内存接口的总线位宽;
- 必须在数据重新使用之前手动存储到 SRAM 中 , 并进行管理以最大限度地减少检索时共享内存库冲突;
- 计算必须在流处理器(SM)内部或之间细致分区和调度 , 以促进指令 / 线程级的并行以及专用算术逻辑单元(ALU)的利用 。
文章图片
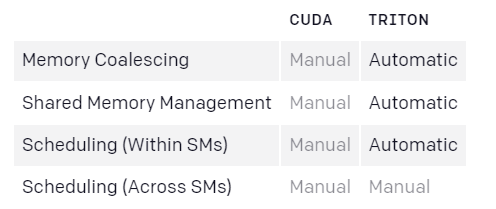
种种因素导致 GPU 编程难度骤增 , 即使对于具有多年经验的 CUDA 程序员也是如此 。 Triton 的目的是将这些优化过程自动化 , 以此让开发人员更专注于并行代码的高级逻辑 。 出于对泛用能力的考量 , Triton 不会自动调度跨流处理器的工作 , 而是将一些重要的算法考虑因素(例如 tiling、SM 间同步)留给开发者自行决定 。
CUDA vs Triton 编译器优化对比 。
文章图片
编程模型
在所有可用的领域专用语言和 JIT 编译器中 , Triton 或许与 Numba 最相似:内核被定义为修饰过的 Python 函数 , 并与实例网格上不同的 program_id 的同时启动 。 但不同之处值得注意:如下图代码片段所示 , Triton 通过对 block 的操作来展示 intra-instance 并行 , 此处 block 是维数为 2 的幂的数组 , 而不是单指令多线程(SIMT)执行模型 。 如此一来 , Triton 高效地抽象出了与 CUDA 线程 block 内的并发相关的所有问题(比如内存合并、共享内存同步 / 冲突、张量核心调度) 。
Triton 中的向量加法 。

文章图片
虽然这对 embarrassingly 并行(即 element-wise)计算可能没什么帮助 , 但是可以简化更复杂的 GPU 程序的开发 。 例如 , 在融合 softmax 核的情况下 , 对于每个输入张量 X∈R^M×N 来说 , 每个实例对给定输入张量的不同行进行归一化 。 这种并行化策略的标准 CUDA 实现可能难以编写 , 需要线程之间的显式同步 , 因为这种策略并发地减少 X 的同一行 。 而 Triton 很大程度上消除了这种复杂性 , 每个内核实例加载感兴趣的行 , 并使用类似 NumPy 的原语顺序对其进行规范化 。
import triton
import triton.language as tl
@triton.jit
def softmax(Y, stride_ym, stride_yn, X, stride_xm, stride_xn, M, N):
# row index
m = tl.program_id(0)
# col indices
# this specific kernel only works for matrices that
# have less than BLOCK_SIZE columns
BLOCK_SIZE = 1024
n = tl.arange(0, BLOCK_SIZE)
# the memory address of all the elements
# that we want to load can be computed as follows
X = X + m * stride_xm + n * stride_xn
# load input data; pad out-of-bounds elements with 0
x = tl.load(X, mask=n < N, other=-float('inf'))
# compute numerically-stable softmax
z = x - tl.max(x, axis=0)
num = tl.exp(z)
denom = tl.sum(num, axis=0)
y = num / denom
# write back to Y
Y = Y + m * stride_ym + n * stride_yn
tl.store(Y, y, mask=n < N)
import torch
# Allocate input/output tensors
X = torch.normal(0, 1, size=(583, 931), device='cuda')
Y = torch.empty_like(X)
# SPMD launch grid
grid = (X.shape[0], )
# enqueue GPU kernel
softmax[grid](Y, Y.stride(0), Y.stride(1),
X, X.stride(0), X.stride(1),
X.shape[0] , X.shape[1])
在 Triton 中融合 softmax
Triton JIT 把 X、Y 当作指针而不是张量 。 最重要的是 , softmax 这种特殊实现方式在整个规范化过程中保持 SRAM 中 X 的行不变 , 从而在适用时最大限度地实现数据重用(约 32K 列) 。 这与 PyTorch 的内部 CUDA 代码不同 , 后者使用临时内存使其更通用 , 但速度明显变慢(见下图) 。
融合 softmax、M=4096 的 A100 性能 。
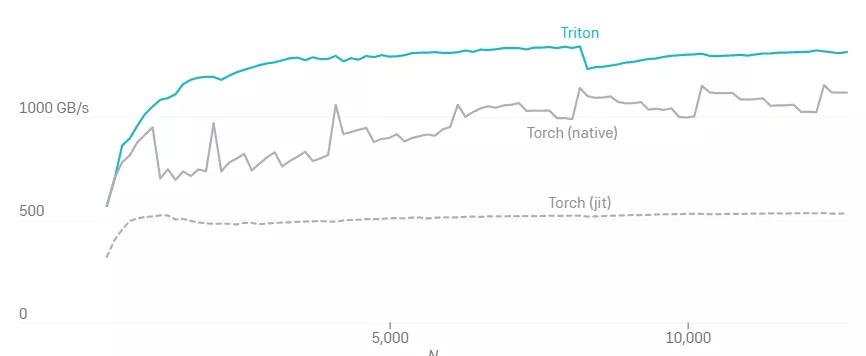
文章图片
Torch (v1.9) JIT 较低的性能突出了从高级张量操作序列自动生成 CUDA 代码的难度 。
@torch.jit.script
def softmax(x):
x_max = x.max(dim=1)[0]
z = x - x_max[:, None]
numerator = torch.exp(x)
denominator = numerator.sum(dim=1)
return numerator / denominator[:, None]
融合 softmax 与 Torch JIT
矩阵乘法
能够为元素操作(element-wise operation)和规约操作(reduction operation)编写融合内核是很重要的 , 但考虑到神经网络中矩阵乘法的重要性 , 这还不够 。 事实证明 , Triton 在这些方面表现很好 , 仅用大约 25 行 Python 代码就能达到最佳性能 。 相比之下 , CUDA 效率就没有那么高了 。

文章图片
Triton 中的矩阵乘法 。
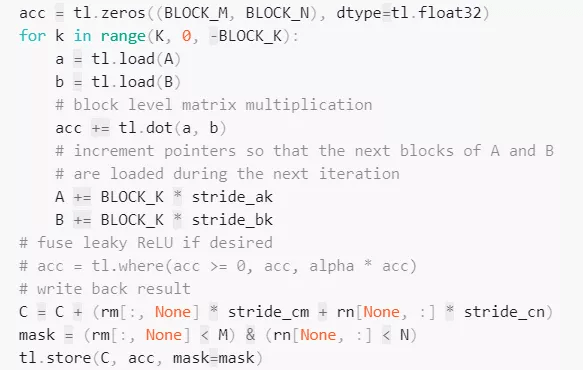
文章图片
手写矩阵乘法内核的一个重要优点是它们可以根据需要进行定制 , 以适应其输入(例如切片)和输出(例如 Leaky ReLU)的融合变换 。 假如不存在 Triton 这样的系统 , 那么对于没有出色的 GPU 编程专业知识的开发人员来说 , 矩阵乘法内核将很难大改 。
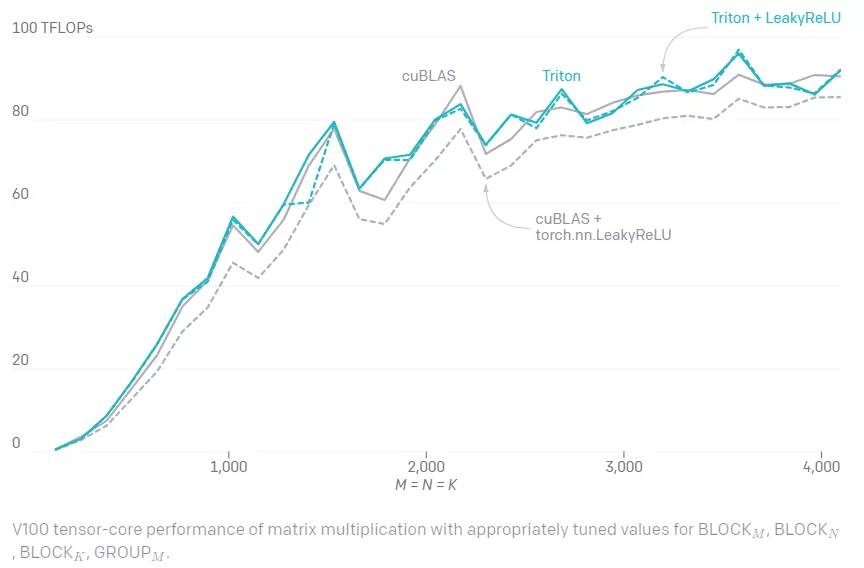
文章图片
高级系统架构
Triton 的良好性能得益于以 Triton-IR 为中心的模块化系统架构 。 Triton-IR 是一种基于 LLVM 的中间表示 , 多维值块(blocks of values)是其中最重要的东西 。
Triton 的高级架构 。

文章图片
@triton.jit 装饰器的工作原理是遍历由 Python 函数提供的抽象语法树(AST) , 这样一来就能使用通用的 SSA 构造算法实时生成 Triton-IR 。 生成的 IR 代码随后由编译器后端进行简化、优化和自动并行化 , 然后转换为高质量的 LLVM-IR , 最终转换为 PTX , 以便在最新的 NVIDIA GPU 上执行 。 目前 Triton 还不支持 CPU 和 AMD GPU , 但团队表示对二者的支持正在开发中 。
编译器后端
研究人员发现通过 Triton-IR 来使用块状程序表示 , 这种方法允许编译器自动执行各种重要的程序优化 。 例如 , 通过查看计算密集型块级操作(例如 tl.dot)的操作数 , 数据可以自动存储到共享内存中 , 并使用标准的活跃性分析技术进行数据的分配与同步 。
Triton 编译器通过分析计算密集型操作中使用的块变量的活动范围来分配共享内存 。

文章图片
此外 , Triton 还可以在 SM 之间以及 SM 之内高效、自动地并行化 , 前者通过并发执行不同的内核实例来实现 , 后者通过分析每个块级操作的迭代空间 , 并将其充分划分到不同的 SIMD 单元来实现 。 如下所示:
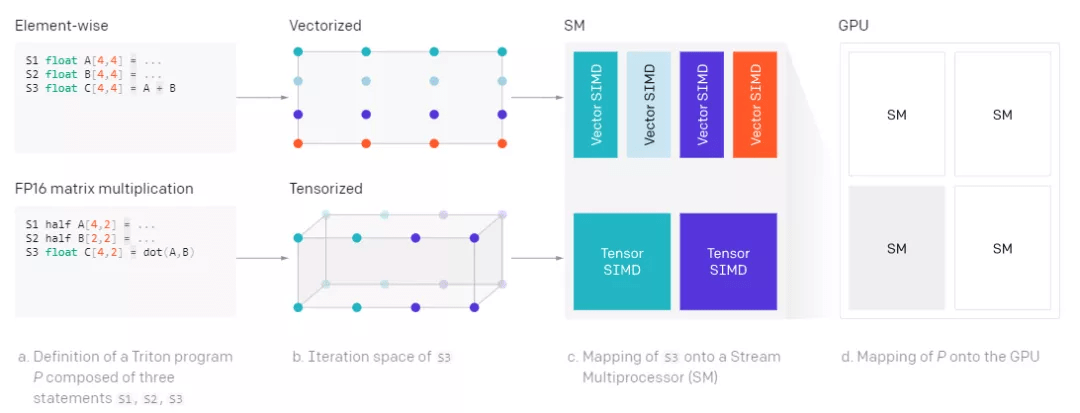
文章图片
Triton 自动并行化 。 每个块级操作都定义了一个块级迭代空间 , 该空间可以自动并行化以利用 SM(Streaming Multiprocessor) 上的可用资源 。
【模型|在CUDA的天下,OpenAI开源GPU编程语言Triton,将同时支持N卡和A卡】参考链接:https://www.openai.com/blog/triton/
推荐阅读





- 星链|石豪:在太空,马斯克和美国当局是如何作恶的
- 建设|这一次,我们用SASE为教育信息化建设保驾护航
- 生活|气笑了,这APP的年度报告是在嘲讽我吧
- 精度|将建模速率提升10倍,消费级3D扫描仪Magic Swift在2021高交会大显“身手”
- 最新消息|世界单体容量最大漂浮式光伏电站在德州并网发电
- 公司|科思科技:正在加速推进智能无线电基带处理芯片的研发
- 测试|图森未来完成全球首次无人驾驶重卡在公开道路的全无人化测试
- Monarch|消息称微软Win11 2022重大更新将在明年夏天到来
- 社交|Facebook被指试图在美政客中抹黑前雇员Frances Haugen声誉
- Intel|Intel在Alder Lake平台演示PM1743 PCIe Gen 5 SSD,带宽达14GB/s