机器之心报道
机器之心编辑部
在 WAIC 2021 AI 开发者论坛上 , 肖嵘发表主题演讲《创「芯」时代 打造自进化城市智能体》 , 在演讲中 , 他主要介绍了自进化城市智能体 , 并介绍了云天励飞最新研究成果及成功案例 。以下为肖嵘在 WAIC 2021 AI 开发者论坛上的演讲内容 , 机器之心进行了不改变原意的编辑、整理:

文章图片
现在 , 人工智能快速应用的过程中会遇到大量的长尾应用算法 , 很多开发者忙着做调参 , 如今有许多新的调参方法 , 使调参这件事变得越来越简单、方便 。 另外还有标注问题 , 做新场景、新场景适应模型等都面临很多困难 。 在这些情况下 , 人工智能整个应用研发最后会变成什么?是大量标注数据、调参吗?显然不是 。 未来智能如何发展?可以说未来整个智能的发展是往自学习、自进化方面进行的 。 我今天演讲的主要内容是关于自进化城市智能体的相关内容 。
智慧城市的发展与面临问题
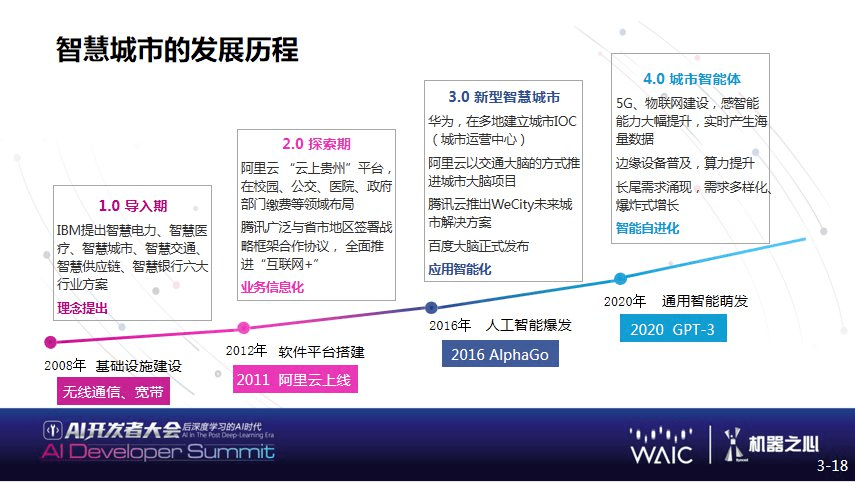
首先智慧城市的发展可分为几个阶段 , 2008 年 IBM 提出智慧城市的概念 , 同时提出了一些行业解决方案 , 但是当时整个网络、算力都有问题 , 智慧城市还处于初级阶段 , 即理念上的概念;2.0 概念大约开始于 2012 年 , 云的概念开始发展 , 例如阿里云开始有云上贵州这样的平台 , 这一阶段主要是平台的解决方案;真正的智能发展其实是 2015、2016 年 , 当时标志性事件 , 例如 AlphaGo 打败人类 , 研究者对智能掀起了很大的热情 。 实际上智能也解决了很多问题 , 当时阿里在智慧交通这一块做了很多工作 。
文章图片
到目前为止 , 时间已经过去了 5 年 , 在这过去的 5 年当中 , 人工智能应用越来越多 , 但同时带来的问题也随之增加 , 目前主要面临三个重要问题 , 此外还有硬件方面问题 。 三个应用方面问题当中 , 主要是需求多样 , 以及两个大的应用部署问题 。
首先当场景发生变化时 , 人工智能模型可能不工作 。 此外相似的场景、相似的需求很多 , 例如今天要去检测路上有没有积水 , 明天要去检测垃圾桶有没有满 , 这种类似的检测问题很多、识别问题也很多 , 目前像这种长尾需求不能得到很好满足 。 以至于到后来大家发现 , 所有的公司都在招 AI 人才 , 因为 AI 应用范围太广 。 市场上所有人工智能企业最痛苦的事情就是招不到人 , 人才招聘也是一个困境 。 第二是可靠性问题 , 现在很多应用都是在云端部署的 , 如果端侧网络出现问题 , 那么用户服务体验就会出现很大问题 。 还有就是安全性问题 , 如果架构都在云端部署 , 未来所有的数据、端侧的海量数据往云端传 , 这样就会带来安全性问题 。 另外 , 还有数据收集有效性问题 , 海量数据往云端传 , 数据流量会不会特别大?此外 , 还有一个问题 , 就是端侧是不是真具有这么大的智能 , 能不能用端侧智能把这些问题解决掉 , 这同样也是一个很大的问题 。 端侧智能还存在部署难等问题 。

文章图片
AI 的普适性
虽然有这么多问题 , 但是我们可以看到智能的发展趋势基本上还是在往自进化城市智能体发展 , 原因在哪?首先自进化城市智能体应该具备两个要素:
- 第一是 AI 的普适性 , 普适性就是 AI 像电力一样无处不在;
- 第二是 AI 整个应用的研发和部署环节 , 一定是自学习、自进化 , 可以自主地演化 。

文章图片
关于普适性问题 , 相对的就是计算无处不在的问题 。 普适计算这个概念讲了很多年 , 它背后的隐藏逻辑是算力的快速提升 。 以 1999-2020 年的 GeForce256 显卡到最新的 RTX3090 为例 , 算力提升了约 400 倍 。 CPU 的性能提升很大 , 网络速度提升也非常明显 。 2000 年时大家还在用 ADSL , 而现在比较快的 5G 网络已达到 20Gb/s 了 。 以此为背景 , 应用研发也发生了很大变化 , 最早单机计算、网络计算、云计算、雾计算 , 此外还有边缘计算 , 计算其实已经开始从云向雾普及 。

文章图片
端侧智能
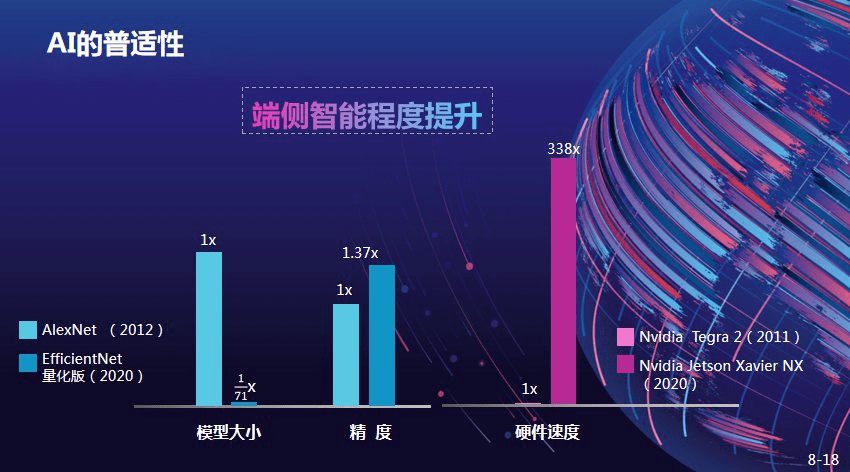
智能在云端已经非常普及 , 未来智能往端侧发展会遇到什么挑战?目前来看已经万事俱备 , 以最经典的 AlexNet 网络为例 , AlexNet 大约在 2012 年被提出 , 精度达到 60% 左右 , 同样的 EfficientNet 模型精度可以提升 1.37 倍 , 而模型尺寸差不多缩小了 71 倍 。 从中我们可以得出模型越来越小、效率却越来越高 。
在端侧应用方面 , 硬件速度提升也非常大 , 以英伟达端侧芯片为例 , 2011 年芯片速度跟 2020 年芯片速度进行比较 , 速度提升了三百多倍 。 可以说端侧整个应用万事俱备 。
文章图片
与端侧智能相对比的是云端智能 , 云端智能面临的问题是高时延、网络的低可靠性 , 数据中心大、不好扩充 , 存在安全隐患以及隐私隐患 。 而端侧智能优势很大 , 可以很好地解决这些问题 , 端侧智能可以实时访问、进行智能的数据筛选和过滤 , 数据隐私保护的也很好 。

文章图片
目前端侧智能普及还面临一些问题、一些挑战 , 可总结为四个方面:芯片指令级效率还需要继续持续提升 , 不够高效;芯片架构不够灵活;处理工具链不易用 , 例如端侧异构性、工具不统一;算法研发周期长、部署困难 。

文章图片
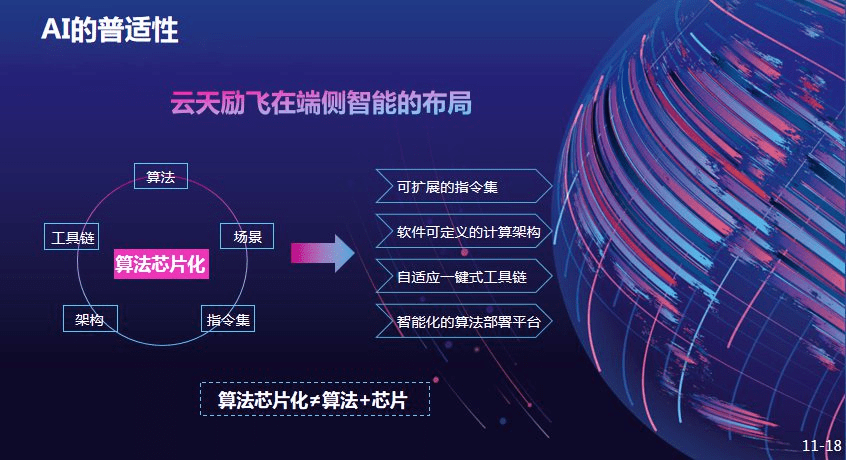
云天励飞端侧布局
云天励飞的端侧布局以算法芯片化布局为例 , 包括算法结合场景 , 打造一系列开放工具链 , 以及开放的架构和高效指令集 。 这些可扩展的指令集、软件可定义的计算架构等使得端侧智能研发和部署周期大幅度提升 。
文章图片
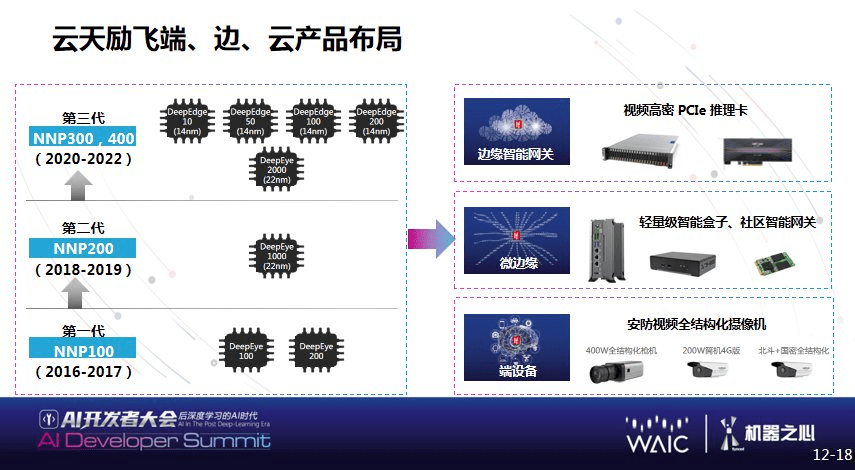
云天励飞产品布局从第一代的 NNP100 已经研发到第三代芯片 , 从最早 22 纳米芯片到 14 纳米芯片 , 同时算力的提升也非常大 。 目前云天励飞在端、边、云都有产品部署 , 并将产品直接应用到结构化端边设备 , 比如抓拍机、监控相机;边缘端有智能网关、智能盒子;云端有高性能的推理卡等 , 云天励飞已经开始全面的端、边、云产品布局 。
文章图片
城市边缘智能平台
对于长尾算法和城市治理问题 , 我们以城市治理为例 , 可以看到有非常复杂的长尾应用:
- 城市管理方面 , 包括重点车辆的监控、游滩小贩等;
- 安全生产方面 , 包括是否符合工艺流程、是否符合防疫标准、是否有非法人员进入等;
- 综合治理方面 , 包括是否有人群聚集、是否有水涝、机动车有没有违停等;
- 生态环境方面 , 包括可以查看水上有没有漂浮物等 。

文章图片
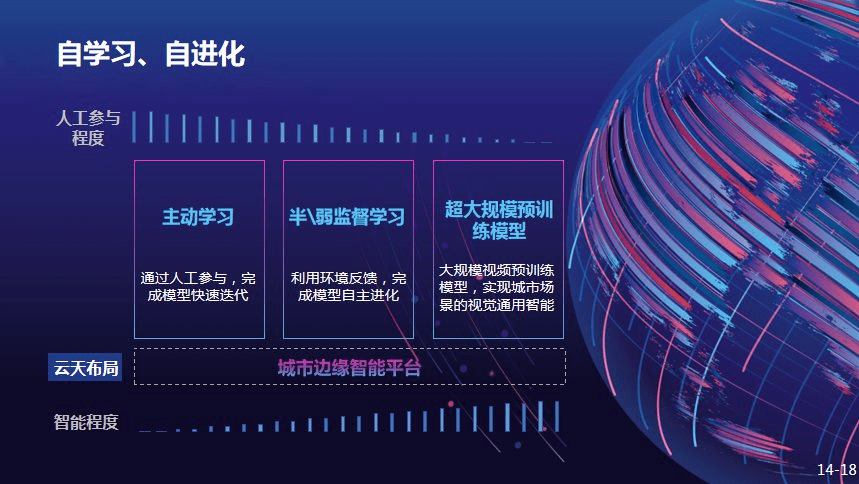
云天励飞提出了城市边缘智能平台概念 , 主要包括三个方向的布局:主动学习;半监督、弱监督学习;超大规模预训练模型 。 从这三个布局可以看到 , 人工智能程度越来越高 , 人工参与就会越来越低 。
以主动学习为例 , 在进行机器学习时 , 我们都知道数据应该是越多越好 , 如果大家学习过统计学理论就会了解 , 以分类为例 , 越位于分类边缘的样本越有信息量 , 反而那些很容易进行分类的样本 , 其实对分类贡献不大 。
文章图片
主动学习的概念就是在无监督样本中 , 主动寻找对分类最有帮助的样本 , 就如同人看一些东西、去学习一些单词 , 大家背单词都会采用主动学习的概念 , 如果背的很熟的单词就不用再去复习了 , 更多的是去复习似是而非、记不住的单词 。 主动学习可以显著通过少量人工参与 , 快速完成模型迭代 。
对于弱监督、半监督学习而言 , 当有大量无标注样本时 , 是否可以学到无标注样本分类特性 , 我们可以主动的引入到学习当中去 , 这样一来就不需要去标注这些数据 。
我们发现真正在城市治理当中处理的是视频数据 , 视频流中隐含了非常多的信息 。 举例来说 , 视频具有时空一致性 , 如果用分类模型做预测 , 大家会观测到什么?如果对人的衣着做分类判断 , 相信在相邻帧的同一个人 , 他的衣着发生变化的概率很低 , 可以认为他的衣着是一致的 。 如果模型预测相邻的二十帧当中 , 发现有十帧是一样的 , 还有十帧预测的非常不好 , 可能这是有问题的样本 , 我们把这个样本拿出来 , 判断是否将这种样本引入 , 去进行学习 。 通过这类引入样本的方法会主动找到有问题样本 , 甚至可以打上伪标签直接用来学习 , 这是非常有效率的方法 。 另外空间运动也存在一致性 , 在追踪当中看到一个人 , 从东往西走 , 如果当中有一帧预测是运动轨迹反过来的 , 就说明运动预测有问题 , 一致性也可以用来帮助研究者自动矫正模型 。 在弱监督、半监督的学习当中 , 通过视频有很多事情可以做 。
另外云天励飞正在做大规模视频预训练模型 。 从 2020 年开始 , Open AI 推出了很多重要研究 , 比如 GPT-3 等大规模自然语言预训练模型的发布 , 云天励飞提出的大规模视频预训练模型 , 也是非常有价值的 。 视频当中有非常丰富的信息 , 一个人在移动的时候 , 如果是静态相机 , 我们就可以知道哪是背景、哪是前景 , 如此就不需要人工做详细标注 , 例如这个人在哪、边缘在哪 。 我们都知道 , 在做视频分割时要标出物体的每个边缘 , 标注量很大 , 通过视频大规模学习 , 我们就可以自动学习分割模型 , 甚至能找出物体的运动逻辑 , 这是我们着力研究的方向 。
云天励飞大规模自学习应用
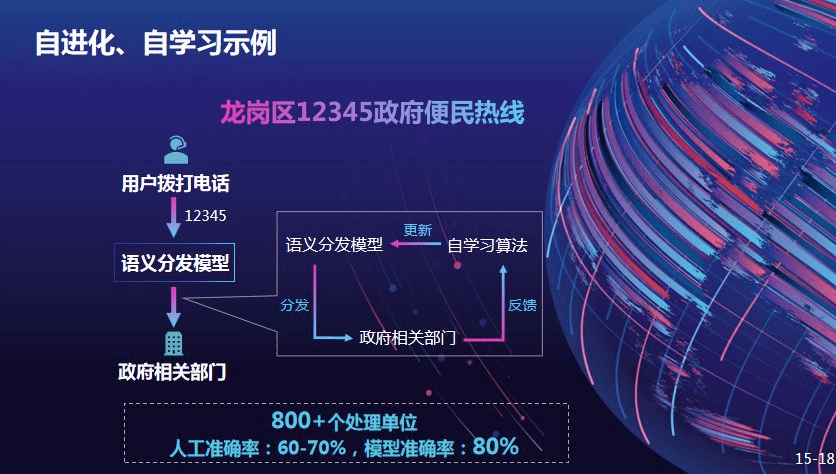
云天励飞大规模自学习应用 , 以龙岗区 12345 政府便民热线为例 , 市民向市政府部门求助的时候会拨打 12345 , 接通之后 , 接线人员会将拨打电话的市民分发到合适部门进行处理 。 但是这个工作有一定的困难 , 一般的二级处理单位可能有八百多个处理单位 , 对于人来说 , 很难将用户精准的分配到准确的位置 , 人工分配的准确率可能有 60% 多 。 模型上线后 , 在持续迭代过程中 , 比如电话打错、用户分发不对等信息 , 这些反馈信息都是非常有价值的 , 根据这些反馈信息重新优化这个模型 , 经过短期迭代 , 模型性能超过 80% 。
文章图片
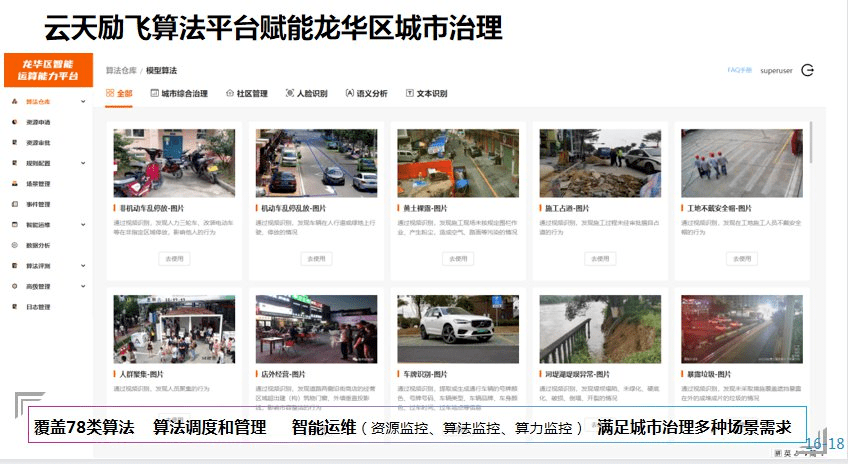
另外 , 云天励飞在龙华区参与了城市治理的项目 , 大约有 20 多个项目场景 , 覆盖 78 类算法 , 其中云天励飞整个平台完成了算法调度、管理、智能运维 , 可以在复杂长尾应用当中快速的进行落地 。
文章图片
【进化|WAIC 2021 | 云天励飞副总裁肖嵘:创「芯」时代 打造自进化城市智能体】云天励飞算法平台基于四个准则:平台开放、算法开源、标准开放、成果共享 。 目前云天励飞生态环境已有很多生态伙伴一起合作 , 一起协同构建城市的智能赋能底座 。
推荐阅读



- Google|谷歌暂缓2021年12月更新推送 调查Pixel 6遇到的掉线断连问题
- 精度|将建模速率提升10倍,消费级3D扫描仪Magic Swift在2021高交会大显“身手”
- 四平|智慧城市“奥斯卡”揭晓!祝贺柯桥客户荣获2021世界智慧城市治理大奖
- 系列|2021中国航天发射圆满收官!年发射55次居世界第一
- 项目|常德市二中2021青少年科技创新大赛再获佳绩
- 选型|数据架构选型必读:2021上半年数据库产品技术解析
- 殊荣|蝉联殊荣!数梦工场荣获DAMA2021数据治理三项大奖
- 公司|外媒:2021,人类太空事业的重大年份
- 语境|B站2021个人年度报告发布:你共计看了多少个视频
- 最新消息|IT系统出错 英国银行给7.5万人多发11亿工资