文章图片
一、什么是数据挖掘
数据挖掘就是从大量的数据中去发现有用的信息 , 然后根据这些信息来辅助决策 。 听起来是不是跟传统的数据分析很像呢?实际上 , 数据挖掘就是智能化的数据分析 , 它们的目标都是一样的 。 但是 , 又有很大的区别 。传统的数据分析和数据挖掘最主要的区别就是在揭示数据之间的关系上 。 传统的数据分析揭示的是已知的、过去的数据关系 , 数据挖掘揭示的是未知的、将来的数据关系 。 它们采用的技术也不一样 , 传统的数据分析采用计算机技术 , 而数据挖掘不仅采用计算机技术 , 还涉及到统计学、模型算法等技术 , 相对来说会复杂很多 。 因为数据挖掘发现的是将来的信息 , 所以最主要就是用来:预测!预测公司未来的销量 , 预测产品未来的价格等等 。
二、数据挖掘的流程
数据挖掘有一套标准的流程 , 可以对数据进行各种科学的处理和预测 , 从而发现数据本身隐藏的规律 。 具体流程如下:
第一步:业务理解 。 明确目标 , 明确分析需求 。
第二步:数据准备 。 收集原始数据、检验数据质量、整合数据、格式化数据 。
第三步:建立模型 。 选择建模技术、参数调优、生成测试计划、构建模型 。
第四步:评估模型 。 对模型进行全面的评估 , 评估结果、重审过程 。
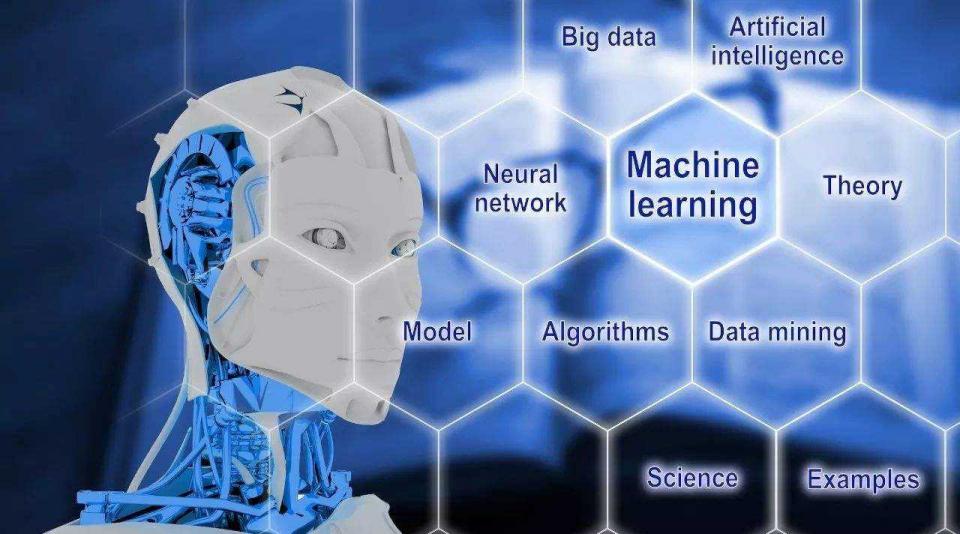
三、算法简介
文章图片
数据挖掘整个流程最关键是模型的迭代优化过程 , 如图Smartbi Mining使用到模型算法有分类算法、回归算法、聚类算法等 , 每种算法类型又包含多种不同的算法 , 例如分类算法 , 就包含逻辑回归、朴素贝叶斯、决策树等 。
下面一一介绍给大家 。
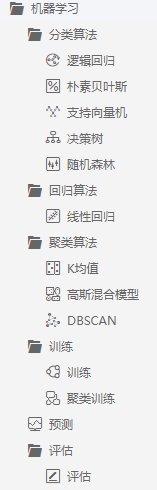
(一)逻辑回归:是机器学习从统计领域借鉴的另一种技术 。 这是二分类问题的专用方法(两个类值的问题) 。
逻辑回归与线性回归类似 , 这是因为两者的目标都是找出每个输入变量的权重值 。 与线性回归不同的是 , 输出的预测值得使用称为逻辑函数的非线性函数进行变换 。
逻辑函数看起来像一个大S , 并能将任何值转换为0到1的范围内 。 这很有用 , 因为我们可以将相应规则应用于逻辑函数的输出上 , 把值分类为0和1(例如 , 如果IF小于0.5 , 那么输出1)并预测类别值 。
由于模型的特有学习方式 , 通过逻辑回归所做的预测也可以用于计算属于类0或类1的概率 。 这对于需要给出许多基本原理的问题十分有用 。 与线性回归一样 , 当你移除与输出变量无关的属性以及彼此非常相似(相关)的属性时 , 逻辑回归确实会更好 。 这是一个快速学习和有效处理二元分类问题的模型 。
文章图片
(二)朴素贝叶斯:朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法 。
朴素贝叶斯是一种简单但极为强大的预测建模算法 。 叫它朴素贝叶斯分类是因为这种方法的思想真的很朴素 , 朴素贝叶斯的思想基础是:对于给出的待分类项 , 求解在此项出现的条件下各个类别出现的概率 , 哪个最大 , 就认为此待分类项属于哪个类别 。
该模型由两种类型的概率组成 , 可以直接从你的训练数据中计算出来:1)每个类别的概率; 2)给定的每个x值的类别的条件概率 。 一旦计算出来 , 概率模型就可以用于使用贝叶斯定理对新数据进行预测 。 当你的数据是数值时 , 通常假设高斯分布(钟形曲线) , 以便可以轻松估计这些概率 。
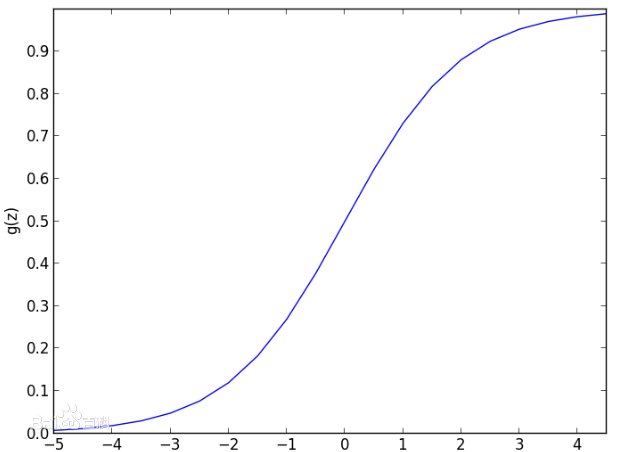
(三)支持向量机:支持向量机(Support Vector Machine, SVM)是一类按监督学习方式对数据进行二元分类的广义线性分类器 , 支持向量机也许是最受欢迎和讨论的机器学习算法之一 。 其决策边界是对学习样本求解的最大边距超平面 。
超平面是分割输入变量空间的线 。 在SVM中 , 会选出一个超平面以将输入变量空间中的点按其类别(0类或1类)进行分离 。 在二维空间中可以将其视为一条线 , 所有的输入点都可以被这条线完全分开 。 SVM学习算法就是要找到能让超平面对类别有最佳分离的系数 。
超平面和最近的数据点之间的距离被称为边界 , 有最大边界的超平面是最佳之选 。 同时 , 只有这些离得近的数据点才和超平面的定义和分类器的构造有关 , 这些点被称为支持向量 , 他们支持或定义超平面 。 在具体实践中 , 我们会用到优化算法来找到能最大化边界的系数值 。
【模型|思迈特软件Smartbi:关于数据挖掘你知道多少呢?】 SVM可能是最强大的即用分类器之一 , 在你的数据集上值得一试 。
文章图片
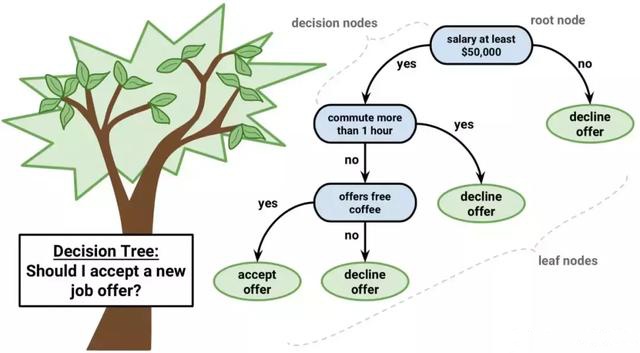
(四)决策树:决策树(Decision Tree)是在已知各种情况发生概率的基础上 , 通过构成决策树来求取净现值的期望值大于等于零的概率 , 评价项目风险 , 判断其可行性的决策分析方法 , 是直观运用概率分析的一种图解法 。 由于这种决策分支画成图形很像一棵树的枝干 , 故称决策树 。
在机器学习中 , 决策树是一个预测模型 , 他代表的是对象属性与对象值之间的一种映射关系 。 Entropy = 系统的凌乱程度 , 使用算法ID3, C4.5和C5.0生成树算法使用熵 。 这一度量是基于信息学理论中熵的概念 。
决策树是一种树形结构 , 其中每个内部节点表示一个属性上的测试 , 每个分支代表一个测试输出 , 每个叶节点代表一种类别 。
分类树(决策树)是一种十分常用的分类方法 。 他是一种监管学习 , 所谓监管学习就是给定一堆样本 , 每个样本都有一组属性和一个类别 , 这些类别是事先确定的 , 那么通过学习得到一个分类器 , 这个分类器能够对新出现的对象给出正确的分类 。 这样的机器学习就被称之为监督学习 。
文章图片
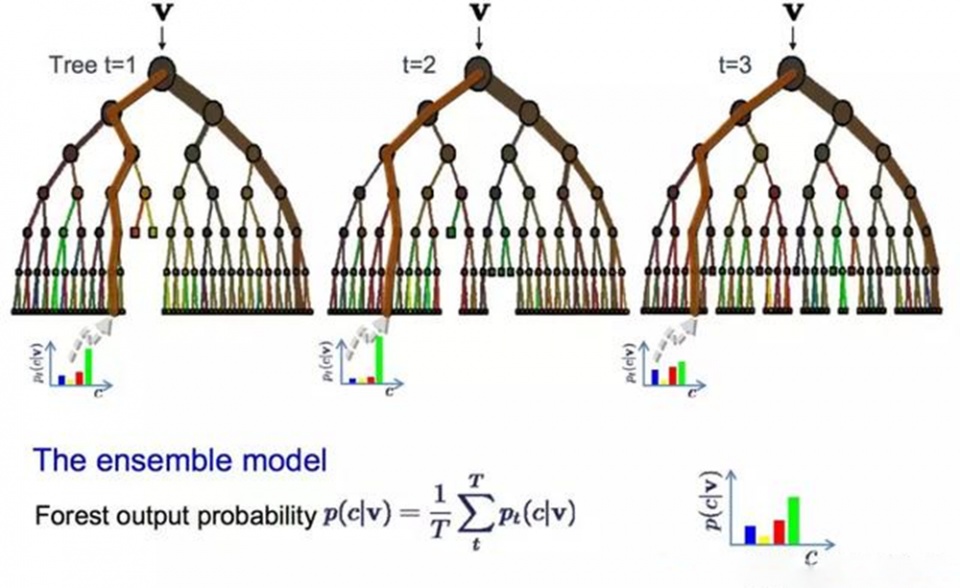
(五)随机森林:随机森林指的是利用多棵树对样本进行训练并预测的一种分类器 。
在机器学习中 , 随机森林是一个包含多个决策树的分类器 , 并且其输出的类别是由个别树输出的类别的众数而定 。
随机森林是最流行和最强大的机器学习算法之一 。它是一种被称为Bootstrap Aggregation或Bagging的集成机器学习算法 。
bootstrap是一种强大的统计方法 , 用于从数据样本中估计某一数量 , 例如平均值 。它会抽取大量样本数据 , 计算平均值 , 然后平均所有平均值 , 以便更准确地估算真实平均值 。
在bagging中用到了相同的方法 , 但最常用到的是决策树 , 而不是估计整个统计模型 。 它会训练数据进行多重抽样 , 然后为每个数据样本构建模型 。 当你需要对新数据进行预测时 , 每个模型都会进行预测 , 并对预测结果进行平均 , 以更好地估计真实的输出值 。
随机森林是对决策树的一种调整 , 相对于选择最佳分割点 , 随机森林通过引入随机性来实现次优分割 。 因此 , 为每个数据样本创建的模型之间的差异性会更大 , 但就自身意义来说依然准确无误 。 结合预测结果可以更好地估计正确的潜在输出值 。
如果你使用高方差算法(如决策树)获得良好结果 , 那么加上这个算法后效果会更好 。
文章图片
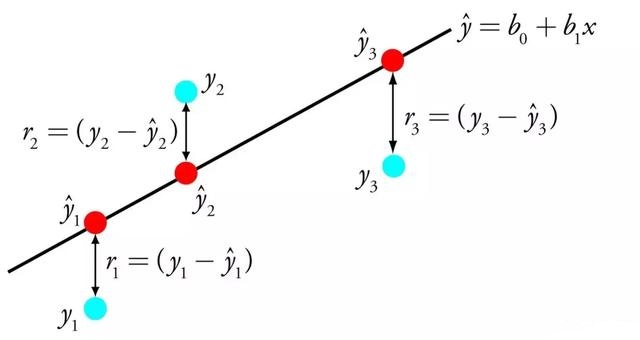
(六)线性回归:线性回归是利用数理统计中回归分析 , 来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法 , 运用十分广泛 。 回归分析中 , 只包括一个自变量和一个因变量 , 且二者的关系可用一条直线近似表示 , 这种回归分析称为一元线性回归分析 。 如果回归分析中包括两个或两个以上的自变量 , 且因变量和自变量之间是线性关系 , 则称为多元线性回归分析 。
一元线性回归用一个等式表示 , 通过找到输入变量的特定权重(B) , 来描述输入变量(x)与输出变量(y)之间的线性关系 。 举例:y = B0 + B1* x 。 给定输入x , 我们将预测y , 线性回归学习算法的目标是找到系数B0和B1的值 。
线性回归已经存在了200多年 , 并且已经进行了广泛的研究 。 如果可能的话 , 使用这种技术时的一些经验法则是去除非常相似(相关)的变量并从数据中移除噪声 。
文章图片
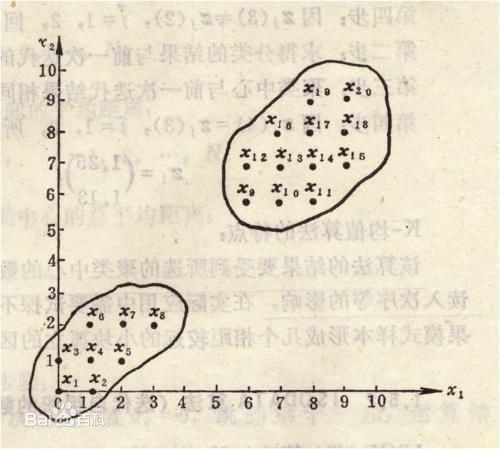
(七)K均值:K均值聚类算法是先随机选取K个对象作为初始的聚类中心 。 然后计算每个对象与各个种子聚类中心之间的距离 , 把每个对象分配给距离它最近的聚类中心 。 聚类中心以及分配给它们的对象就代表一个聚类 。 一旦全部对象都被分配了 , 每个聚类的聚类中心会根据聚类中现有的对象被重新计算 。 这个过程将不断重复直到满足某个终止条件 。 终止条件可以是没有(或最小数目)对象被重新分配给不同的聚类 , 没有(或最小数目)聚类中心再发生变化 , 误差平方和局部最小 。
聚类是一个将数据集中在某些方面相似的数据成员进行分类组织的过程 , 聚类就是一种发现这种内在结构的技术 , 聚类技术经常被称为无监督学习 。
k均值聚类是最著名的划分聚类算法 , 由于简洁和效率使得他成为所有聚类算法中最广泛使用的 。 给定一个数据点集合和需要的聚类数目k , k由用户指定 , k均值算法根据某个距离函数反复把数据分入k个聚类中 。
文章图片
(八)高斯混合模型:高斯混合模型就是用高斯概率密度函数(正态分布曲线)精确地量化事物 , 它是一个将事物分解为若干的基于高斯概率密度函数(正态分布曲线)形成的模型 。 而估计的模型是几个高斯模型加权之和(具体是几个要在模型训练前建立好) 。 每个高斯模型就代表了一个类(一个Cluster) 。 对样本中的数据分别在几个高斯模型上投影 , 就会分别得到在各个类上的概率 。 然后我们可以选取概率最大的类所为判决结果 。
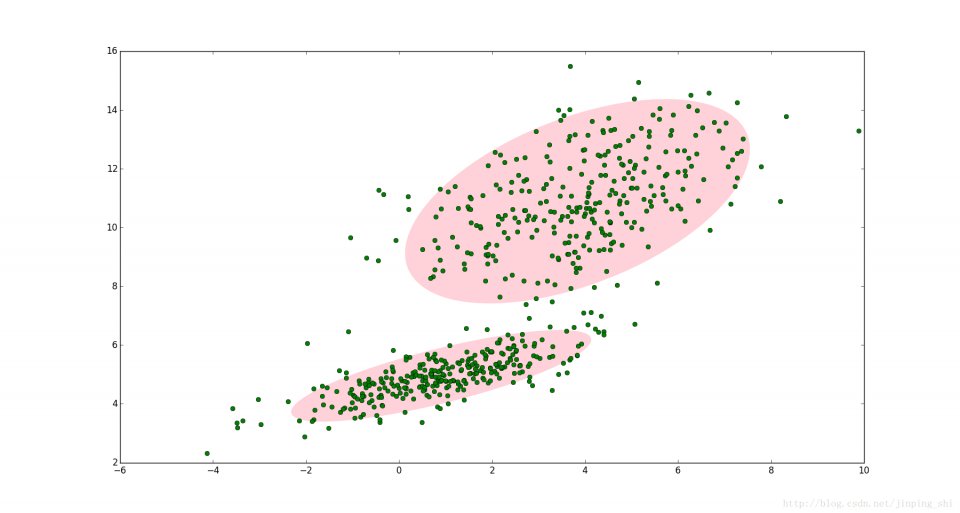
文章图片
(九)DBSCAN:DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一个比较有代表性的基于密度的聚类算法 。 与划分和层次聚类方法不同 , 它将簇定义为密度相连的点的最大集合 , 能够把具有足够高密度的区域划分为簇 , 并可在噪声的空间数据库中发现任意形状的聚类 。
同一类别的样本 , 他们之间的紧密相连的 , 也就是说 , 在该类别任意样本周围不远处一定有同类别的样本存在 。 通过将紧密相连的样本划为一类 , 这样就得到了一个聚类类别 。 通过将所有各组紧密相连的样本划为各个不同的类别 , 则我们就得到了最终的所有聚类类别结果 。
看了上面这么多算法 , 大家听了是不是觉得很专业、很复杂?
数据挖掘真的那么难么?今天给大家推荐一款简单易用的工具——Smartbi Mining , 是由Smartbi推出的独立产品 , 旨在为个人、团队、企业所做的决策提供预测性分析 。
Smartbi Mining具有流程化、可视化的建模界面 , 内置实用的、经典的统计挖掘算法和深度学习算法 , 并支持Python扩展算法 , 基于分布式云计算 , 可以将模型发送到Smartbi统一平台 , 与BI平台完美整合 。
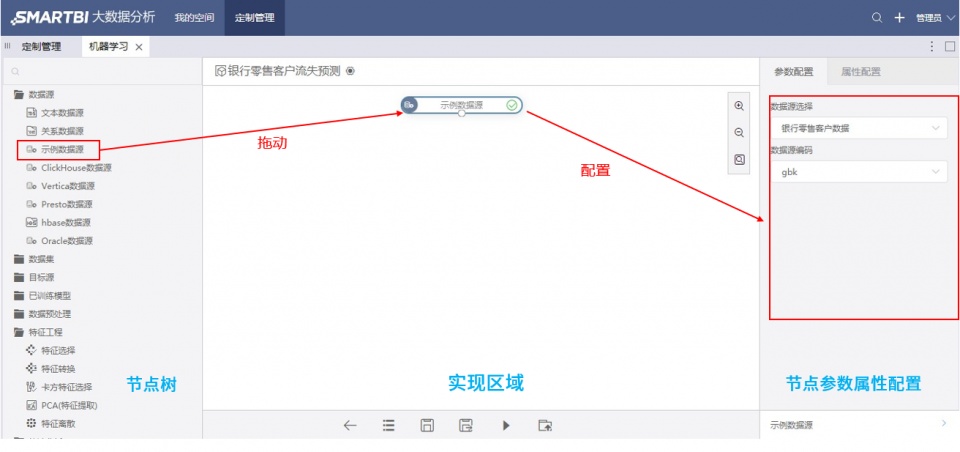
操作界面如下:最左侧是节点树 , 包含了已经开发好的所有节点 。 中间是主要实现区域 , 将节点之间拖拽过来即可 。 右侧是节点的参数配置和属性配置 。
文章图片
Smartbi Mining通过提供基于Web的可视化的界面 , 数据挖掘的每一步流程通过功能点的拖动和参数(属性)配置即可实现 。 简单拖拉拽就可轻松完成预测 , 实在是太方便!
推荐阅读







- 相关|科思科技:无人机地面控制站相关设备产品开始逐步发力
- 公司|科思科技:正在加速推进智能无线电基带处理芯片的研发
- AMD|AMD 350亿美元收购赛灵思交易完成时间推迟 预计明年一季度完成
- 解决方案|蓝思科技:两智能制造项目入选工信部示范工厂揭榜单位和优秀解决方案榜单
- 刘思远|从1到100 这座“塔”不断创造中国航天奇迹
- 意思|森海新的TWS有点小HD660S的意思?森海老粉对CX Plus的一点看法
- Waymo|PayPal CEO:积极在日本展开收购,开拓支付市场;网易入股虚拟数字研发商世悦星承 | 思维独角兽
- 模型|2022前展望大模型的未来,周志华、唐杰、杨红霞这些大咖怎么看?
- 能源|新思科技葛群:以科技重塑能源格局,助力双碳目标实现
- 维修|思科MX800维修大屏更换调试案例 视频会议设备湖北武汉、辽宁沈阳两地同步维修