机器之心报道
机器之心编辑部
来自谷歌的研究团队表明 , 将傅里叶变换取代 transformer 自监督子层 , 可以在 GLUE 基准测试中实现 92% 的准确率 , 在 GPU 上的训练时间快 7 倍 , 在 TPU 上的训练时间快 2 倍 。
Transformer 自 2017 年推出以来 , 其架构就开始在 NLP 领域占据主导地位 。 Transformer 应用的唯一限制之一 , 即 Transformer 关键组件的巨大计算开销–一种自注意力机制 , 这种机制可以根据序列长度以二次复杂度进行扩展 。
基于此 , 来自谷歌的研究者建议用简单的线性变换替代自注意力子层 , 该线性变换「混合」输入 token , 以较小的准确率成本损失显著的提高了 transformer 编码器速度 。 更令人惊讶的是 , 研究者发现采用标准的、非参数化的傅里叶变换替代自注意力子层 , 可以在 GLUE 基准测试中实现 92% 的 BERT 准确率 , 在 GPU 上的训练时间快 7 倍 , 在 TPU 上的训练时间快 2 倍 。

文章图片
论文链接:https://arxiv.org/pdf/2105.03824.pdf
该研究的主要贡献包括:
通过用标准的非参数化傅里叶变换代替注意力子层 , FNet 在 GLUE 基准测试中实现 92% 的 BERT 准确率 , 在 GPU 上的训练时间快 7 倍 , 在 TPU 上的训练时间快 2 倍 。
仅包含两个自注意子层的 FNet 混合模型在 GLUE 基准上可达到 97%的 BERT 准确率 , 但在 GPU 上的训练速度快近 6 倍 , 而在 TPU 上则是 2 倍 。
FNet 在「Long Range Arena」基准评估中 , 与所有的高效 transformer 具有竞争力 , 同时在所有序列长度上拥有更少的内存占用 。
FNet 架构
Transformer 自注意力机制使得输入可以用高阶单元表示 , 从而可以灵活地捕获自然语言中各种语法和语义关系 。 长期以来 , 研究人员一直认为 , 与 Transformer 相关的高复杂性和内存占用量是不可避免的提高性能的折衷方案 。 但是在本论文中 , Google 团队用 FNet 挑战了这一思想 , FNet 是一种新颖的模型 , 在速度、内存占用量和准确率之间取得了很好的平衡 。
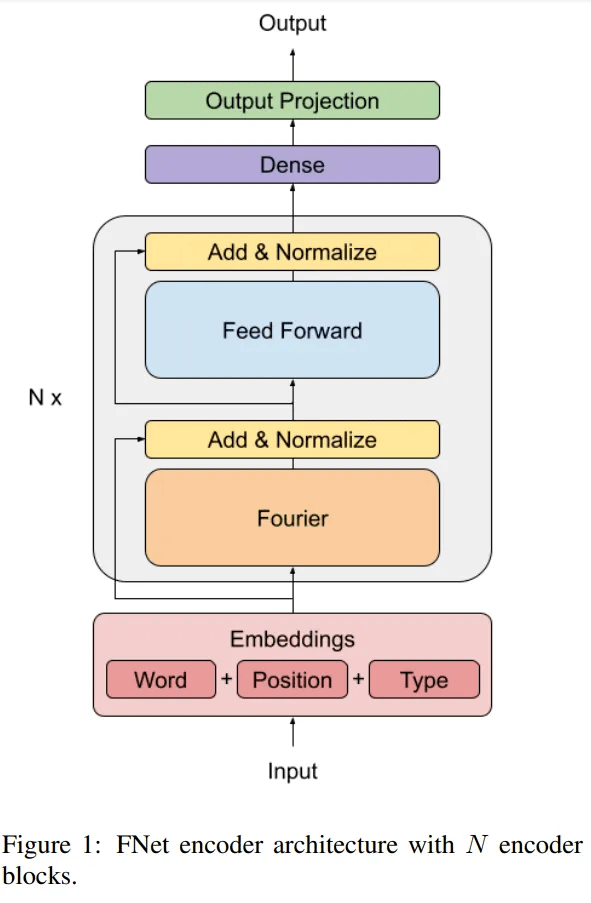
文章图片
FNet 架构 。
FNet 是具有多个层的层归一化 ResNet 体系结构 , 每个层都由一个傅里叶混合子层和一个前馈子层组成 。 研究者将每个 transformer 编码器层的自注意力子层替换为傅里叶变换子层 , 该子层将 2D 傅里叶变换应用于其(序列长度、隐藏维度)嵌入输入 - 沿着序列维度和隐藏维度进行一维傅立叶变换 。
所得结果是一个复数 , 可以将其写成实数乘以虚数单位(数学中的数字 i , 从而可以求解没有实数解的方程式) 。 最后仅保留实数 , 无需修改(非线性)前馈子层或输出层以处理复数 。
实验
在评估中 , 研究者比较了多个模型 , 包括 BERT-Base、FNet 编码器(用傅里叶子层替换每个自注意力子层)、线性编码器(用线性子层替换每个自注意力子层)、随机编码器( 用常数随机矩阵替换每个自注意力子层)、仅前馈编码器(从 Transformer 层中删除自注意力子层) 。
由下表 3 可得 , 尽管线性模型和 FNet 训练的精确率略低 , 但它们明显快于 BERT——在 TPU 上大约快 2 倍 , 在 GPU 上大约快 7 倍 。
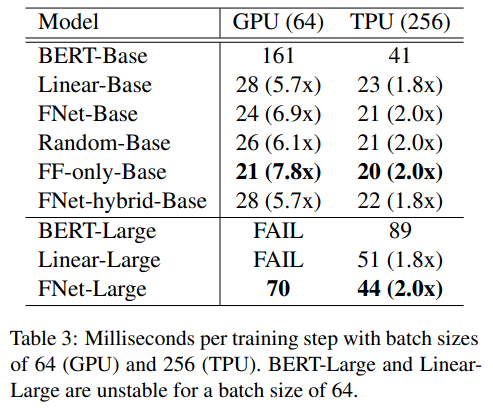
文章图片
下表 4 的 GLUE 验证分组中展示了最佳基础学习率的结果:
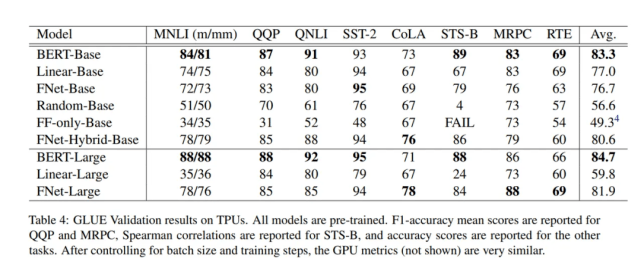
文章图片
下图 2 和图 3 显示了 GPU(8 个 V100 芯片)和 TPU(4×4 TPU v3 芯片)预训练的速度与 MLM 准确率曲线 。
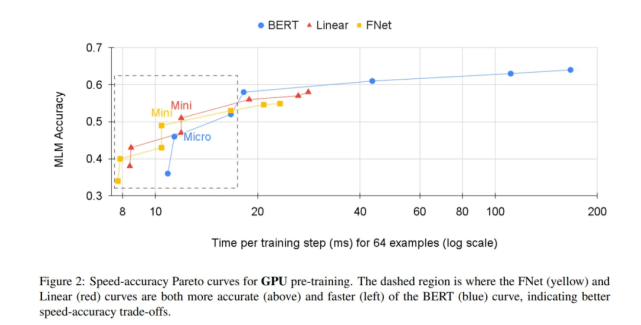
文章图片
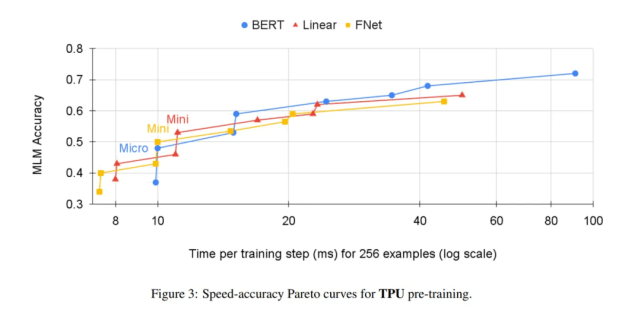
文章图片
研究者还利用 Tay 等人代码库 , 并在相同的硬件(4 × 4 TPU v3 芯片)上进行实验 。 为了确保实验的公平性 , 他们还展示了 Long-Range Arena 实验结果 。
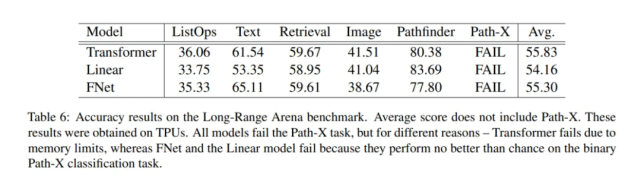
文章图片
在下表 7 和表 8 中 , 研究者还提供了在 TPU(4×4 TPU v3 芯片)和 GPU(8 V100 芯片)上进行实验的可比指标 。 研究者在序列长度 上执行网格搜索 , 而不仅仅是 。 此外 , 该研究还包括 Performer 的结果(Choromanski 等人 , 2020b) 。 在比较模型效率时 , 研究者将 Performer 用作衡量标准 。
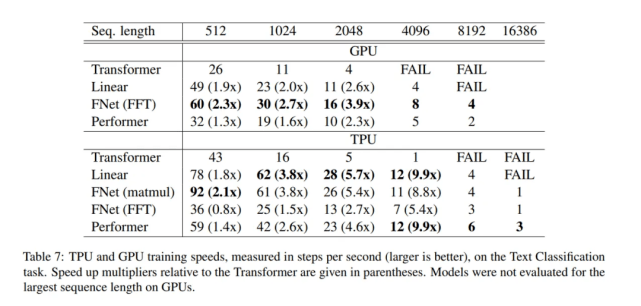
文章图片
【长度|傅里叶变换取代Transformer自注意力层,谷歌这项研究GPU上快7倍、TPU上快2倍】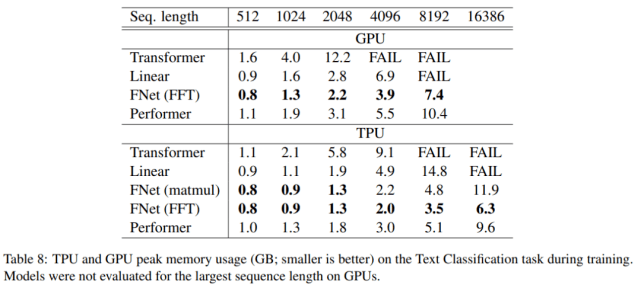
文章图片
推荐阅读



- 男子|美国黑岩沙漠中发现史前“海怪” 头部长度相当于成年男子身高
- 长度|开发者分享 Steam Deck 开箱试玩视频,长度接近 MacBook Air
- 长度|河南省科技馆新馆天文观测“首秀” 100米圭表塔冬至测日影
- 处理|我们计划招收300名数学爱好者,免费系统学习Matlab与傅立叶变换
- 砂岩|长度堪比小汽车 最大千足虫化石现身
- 产品|长度仅 0.25mm,国内厂商宇阳科技推出 008004 超微型 MLCC 电容
- 长度|Minisforum 发布开放式主机,搭载 R5 5600X + RX 6700 XT
- 长度|复旦研究把电池“织”成衣服,随时可给手机充电
- 信息|Transformer又出新变体∞-former:无限长期记忆,任意长度上下文
- 长度|成功研发!靠衣服就能给手机无线充电?