机器之心报道
机器之心编辑部
任意长度的上下文都能 hold 住?这里有一个名为∞-former 的新模型 。在过去的几年里 , Transformer 几乎统治了整个 NLP 领域 , 还跨界到计算机视觉等其他领域 。 但它也有弱点 , 比如不擅长处理较长上下文 , 因为计算复杂度会随着上下文长度的增长而增长 , 这使其难以有效建模长期记忆 。 为了缓解这一问题 , 人们提出了多种 Transformer 变体 , 但它们的记忆容量都是有限的 , 不得不抛弃较早的信息 。
在一篇论文中 , 来自 DeepMind 等机构的研究者提出了一种名为 ∞-former 的模型 , 它是一种具备无限长期记忆(LTM)的 Transformer 模型 , 可以处理任意长度的上下文 。

文章图片
论文链接:https://arxiv.org/pdf/2109.00301.pdf
通过利用连续空间注意力机制来处理长期记忆 , ∞-former 的注意力复杂度可以独立于上下文长度 。 因此 , 它能够借助一个固定的算力开销建模任意长度的上下文并保持「粘性记忆(sticky memories)」 。
在一个综合排序任务上进行的实验证明了∞-former 能够保留来自长序列的信息 。 此外 , 研究者还进行了语言建模的实验 , 包括从头开始训练一个模型以及对一个预训练的语言模型进行微调 , 这些实验显示了无限长期记忆的优势 。
不过 , 和其他很多 Transformer 变体的论文一样 , 这篇论文的标题也引发了一些吐槽:
文章图片
∞-former:一种拥有无限记忆的 Transformer
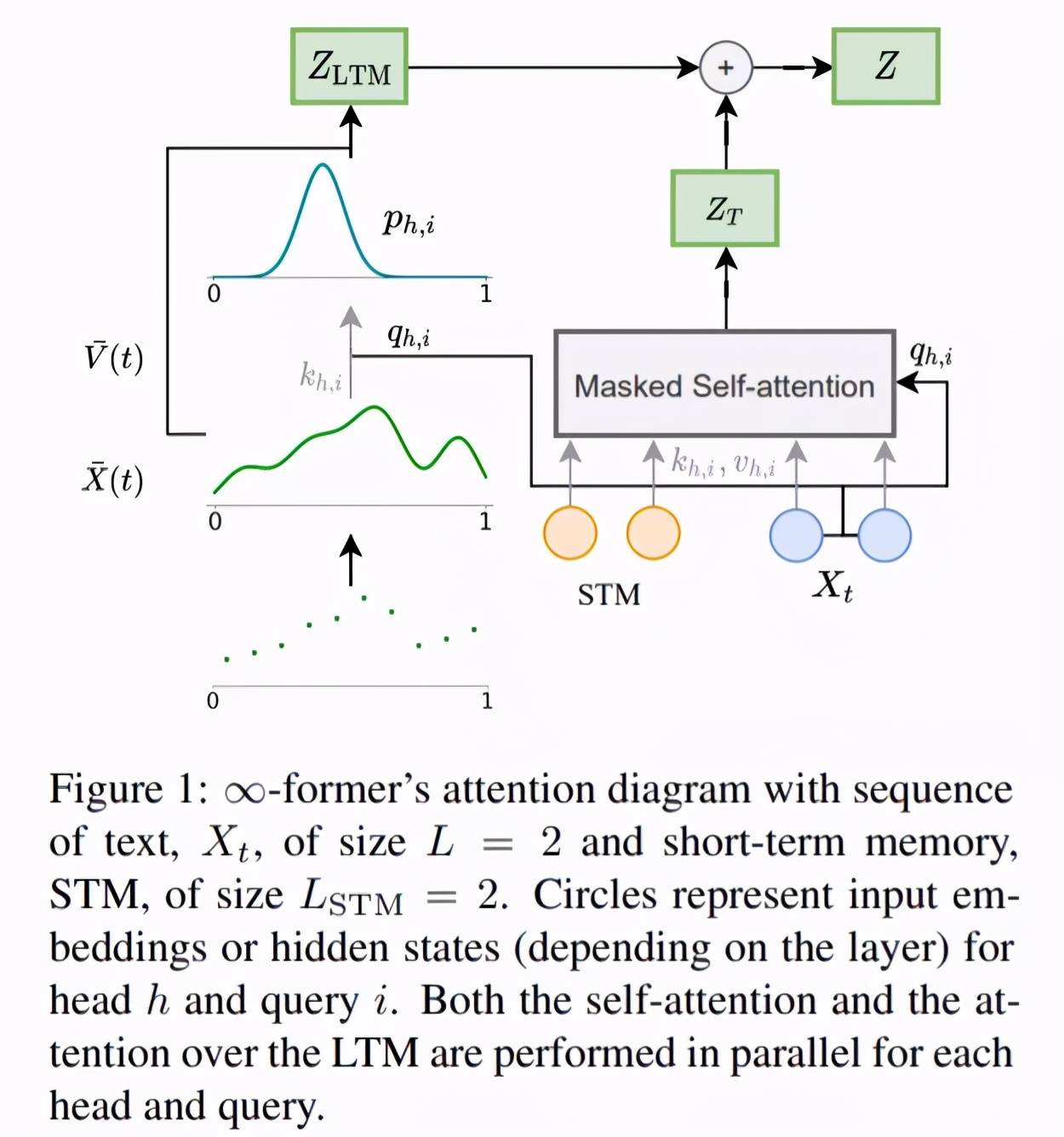
为了使模型能够处理长程上下文 , 研究者提出用一个连续 LTM 来扩展原始 transformer , 这个 LTM 存储前面步骤的输入嵌入和隐藏状态 。 他们还考虑了有两种记忆的可能性:LTM 和 STM(短期记忆) , 类似于 transformer-XL 的记忆 。 ∞-former 的整体架构如下图 1 所示 。
文章图片
为了让新模型的 LTM 达到无限的程度 , 研究者使用了一个连续空间注意力框架(参见《 Sparse and Continuous Attention Mechanisms 》) , 它在适用于记忆的信息单元数量(基函数)和这些单元的表示粒度之间进行了权衡 。 在这一框架中 , 输入序列被表征为一个连续信号 , 表示为径向基函数的一个线性组合 。 这种表征有两个显著的优势:1)上下文可以用 N 个基函数来表示 , N 小于上下文中 token 的数量 , 降低了注意力复杂度;2)N 可以是固定的 , 这使得在记忆中表征无限长度的上下文成为可能(如图 2 所示) , 代价是损失 resolution , 但不增加其注意力复杂度 , O(L^2 + L × N) , 其中的 L 对应 transformer 序列长度 。
推荐阅读








- 建设|这一次,我们用SASE为教育信息化建设保驾护航
- 硬件|又一28nm晶圆厂计划浮出水面 但困难重重
- 领域|上海市电子信息产业“十四五”规划:以集成电路为核心先导
- Tencent|微信小程序新规则:调用个人敏感信息将需授权
- 接口|微信小程序用户信息相关接口调整
- 梦芯|梦芯科技:精准时空信息赋能汽车技术创新发展
- 海康威视|智能家居战场又添一员,海康威视分拆萤石网络上市,半年营收20亿 | IPO见闻
- 人物|继“年度恶人”之后 扎克伯格又被批“殖民”夏威夷
- 解决方案|德国又一州“去微软化”失败,将继续使用 Microsoft Teams
- 手机|又一台Realme XT手机在印度起火 公司正在调查此事