原文链接:http://tecdat.cn/?p=22665
原文出处:拓端数据部落公众号
摘要 状态空间建模是一种高效、灵活的方法 , 用于对大量的时间序列和其他数据进行统计推断 。 本文介绍了状态空间建模 , 其观测值来自指数族 , 即高斯、泊松、二项、负二项和伽马分布 。 在介绍了高斯和非高斯状态空间模型的基本理论后 , 提供了一个泊松时间序列预测的说明性例子 。 最后 , 介绍了与拟合非高斯时间序列建模的其他方法的比较 。
绪论 状态空间模型为几种类型的时间序列和其他数据的建模提供了一个统一的框架 。 结构性时间序列、自回归综合移动平均模型(ARIMA)、简单回归、广义线性混合模型和三次样条平滑模型只是一些可以表示为状态空间模型的统计模型的例子 。 最简单的一类状态空间模型是线性高斯状态空间模型(也被称为动态线性模型) , 经常被用于许多科学领域 。
高斯状态空间模型 本节将介绍有关高斯状态空间模型理论的关键概念 。 由于卡尔曼滤波(Kalman filtering)背后的算法主要是基于Durbin和Koopman(2012)以及同一作者的相关文章 。 对于具有连续状态和离散时间间隔的线性高斯状态空间模型t=1, . . ., n , 我们有
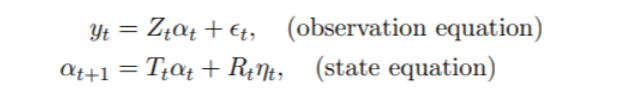
文章图片
其中t~N(0 , Ht) , ηt~N(0 , Qt)和α1~N(a1 , P1)相互独立 。 我们假设yt是一个p×1 , αt+1是一个m×1 , ηt是一个k×1的向量 。 α = (α > 1 , . . . , α> n ) > , 同样y = (y > 1 , . . , y> n ) > 。
状态空间建模的主要目标是在给定观测值y的情况下获得潜状态α的知识 。 这可以通过两个递归算法实现 , 即卡尔曼滤波和平滑算法 。 从卡尔曼滤波算法中 , 我们可以得到先行一步的预测结果和预测误差
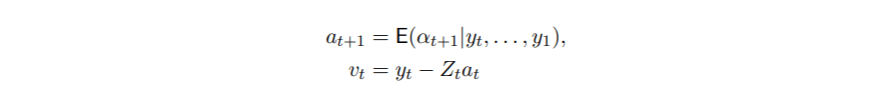
文章图片
和相关的协方差矩阵
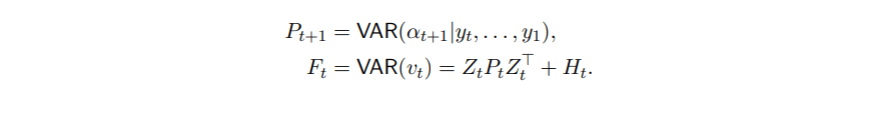
文章图片
利用卡尔曼滤波的结果 , 我们建立了状态平滑方程 , 在时间上向后运行 , 产生了
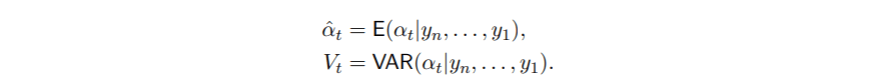
文章图片
对于干扰项t和ηt , 对于信号θt = Ztαt , 也可以计算类似的平滑估计 。
高斯状态空间模型的例子 现在通过例子来说明 。 我们的时间序列包括1969-2007年40-49岁年龄组每年每10万人中酒精相关的死亡人数(图1) 。 数据取自统计局 。 对于观测值 y1, ... . , yn , 我们假设在所有t = 1, . . . , n , 其中μt是一个随机游走的漂移过程
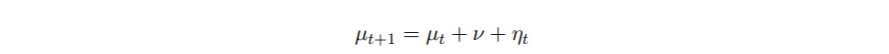
文章图片
ηt~N(0, σ2 η) 。 假设我们没有关于初始状态μ1或斜率ν的先验信息 。 这个模型可以用状态空间的形式来写 , 定义为
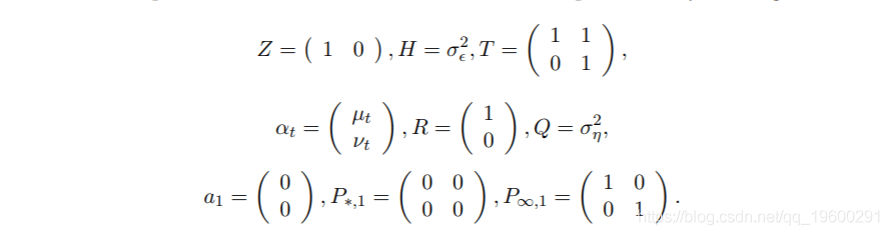
文章图片
在KFAS中 , 这个模型可以用以下代码来写 。 为了说明问题 , 我们手动定义所有的系统矩阵 , 而不采用默认值 。
- R> Zt <- matrix(c(1, 0), 1, 2)
- R> model_gaussian <-Model(deaths / population ~ -1 +custom(Z = Zt)
- KF(fit_gaussian)
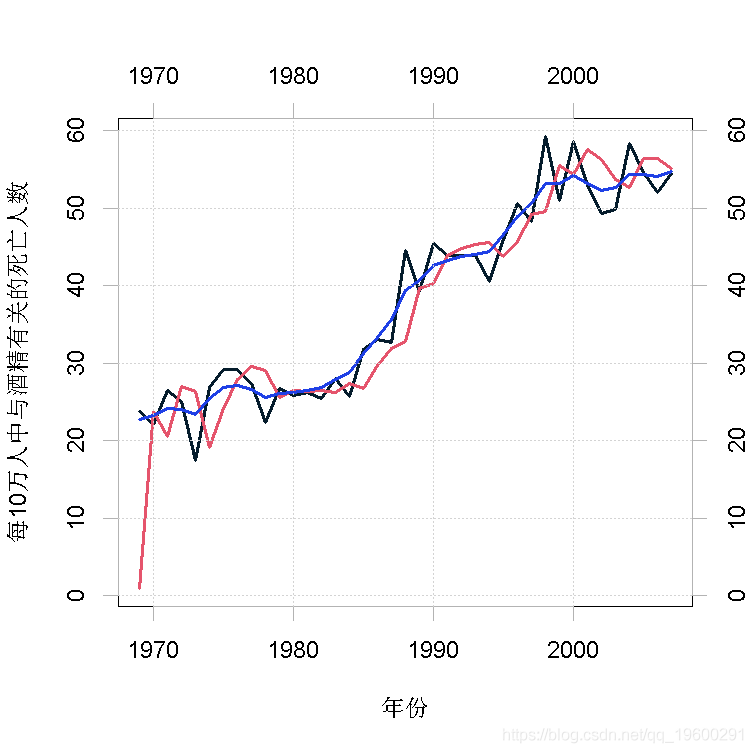
图1显示了带有一步预测(红色)和平滑化(蓝色)的随机行走过程μt的估计值的观察结果 。 请注意典型的模型;在时间t , 卡尔曼滤波器计算一步向前预测误差vt = yt - μt , 并使用它和先前的预测来修正下一个时间点的预测 。 在这里 , 这在系列的开始阶段最容易看到 , 我们的预测似乎落后于观测值一个时间步长 。 另一方面 , 平滑算法同时考虑了每个时间点的过去和未来的数值 , 从而产生了更平滑的潜过程的估计 。
文章图片
非高斯状态空间模型的例子 与酒精有关的死亡也可以自然地被建模为泊松过程 。 现在我们的观测值yt是第t年与酒精有关的死亡的实际计数 , 而变化的人口规模则由暴露项ut来考虑 。 状态方程保持不变 , 但观察方程现在的形式是p(yt |μt) = Poisson(ute μt) 。
- R> Model(deaths ~ -1 +
- + distribution = "poisson")
图2显示了以高斯过程(蓝色)和泊松过程(红色)为模型(每10万人的死亡人数)的平滑估计 。
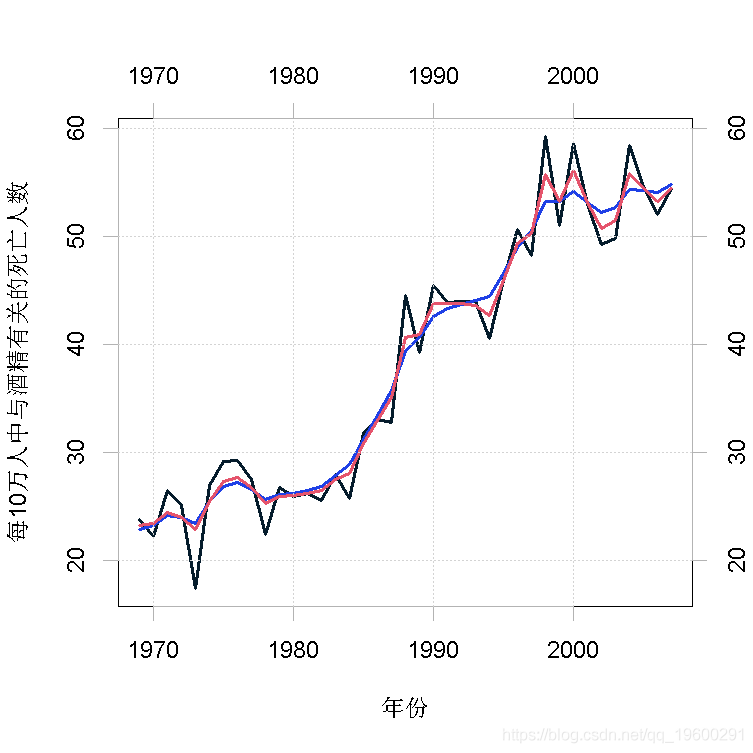
文章图片
任意的状态空间模型 通过结合前面的方法 , 可以相对容易地构建大量的模型 。 对于这样做还不够的情况 , 可以通过直接定义系统矩阵来构建任意状态空间模型 。 作为一个例子 , 我们修改了之前的泊松模型 , 增加了一个额外的白噪声项 , 试图捕捉数据的可能的过度离散 。 现在我们的泊松强度模型是ut exp(μt + t) , 即
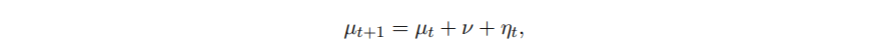
文章图片
其中ηt~N(0, σ2 η)如前 , t~N(0, σ2) 。 这个模型可以用状态空间的形式来写 , 定义为
- Model(deaths ~ trend(2, Q = list(NA, 0)) +
- distribution = "poisson")
- R> update <- function(pars, model) {
- + model[ "custom"] <- exp(pars)
- + }
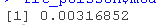
文章图片
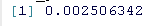
文章图片
从图3中我们看到 , 高斯结构时间序列模型和带有额外白噪声的泊松结构时间序列模型对平滑趋势μt的估计几乎没有区别 。 这是由于泊松过程的强度相对较高 。
文章图片
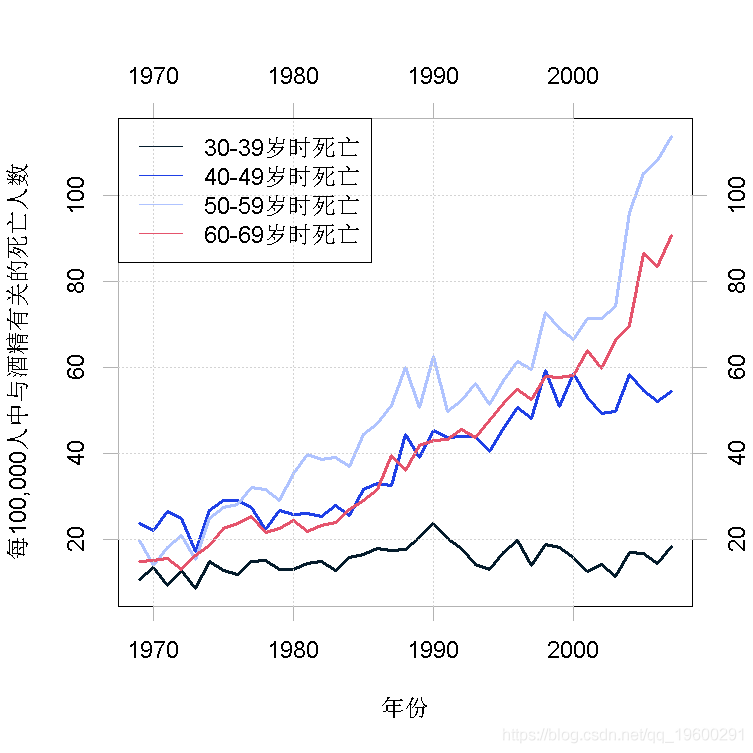
例子 我现在用一个比前面的例子更完整的例子来说明KFAS的使用 。 数据还是由酒精有关的死亡组成 , 但现在有四个年龄组 , 即30-39岁、40-49岁、50-59岁和60-69岁 , 被一起作为一个多变量泊松模型来建模 。
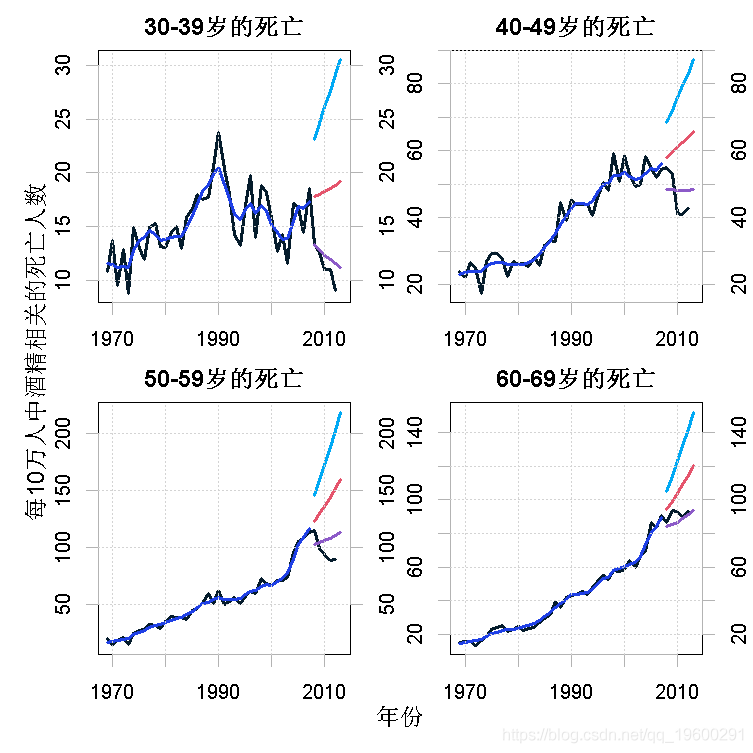
1969-2012年的死亡人数和相应年龄组的年人口规模都有 , 但作为说明 , 我们只使用2007年之前的数据 , 并对2008-2013年进行预测 。 图4显示了所有年龄组的每10万人的死亡人数 。
- ts.plot(window(data[, 1:4] / data[, 5:8], end = 2007)
文章图片
这里我选择了之前使用的泊松模型的一个多变量扩展 。
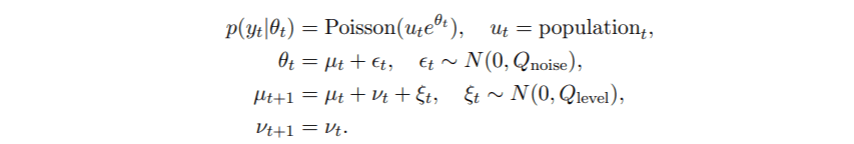
文章图片
这里μt是带有漂移成分的随机游走 , νt是一个恒定的斜率 , t是一个额外的白噪声成分 , 用于捕捉序列的额外变化 。 我对水平和噪声成分的协方差结构不做限制 。 模型(4)可以用KFAS构建如下 。
- R> Model(Pred[, 1:4] ~
- + trend(2, Q = list(matrix(NA, 4, 4))
- distribution = "poisson"
- R> updatefn <- function(pars, model, ...){
- + model[ etas ] <- crossprod(Q)
- + crossprod(Q)
- + model
- + }
- fit(model, update,
- + method = "BFGS")
- R> fit <- fit(model, updatefn = updatefn, inits =optimpar)
文章图片
文章图片
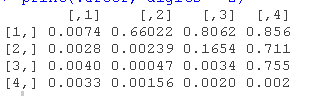
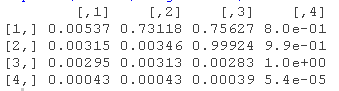
使用拟合模型的提取方法 , 我们可以检查估计的协方差和相关矩阵 。
- R> varcordel["Q", "level"]
- R> varcordel["Q", "custom"]
文章图片
文章图片
状态空间模型的参数估计通常工作量很大 , 因为似然面包含多个最大值 , 从而使优化问题高度依赖于初始值 。 通常情况下 , 未知参数与未观察到的潜在状态有关 , 如本例中的协方差矩阵 , 几乎没有先验知识 。
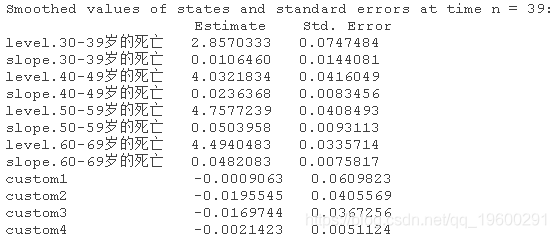
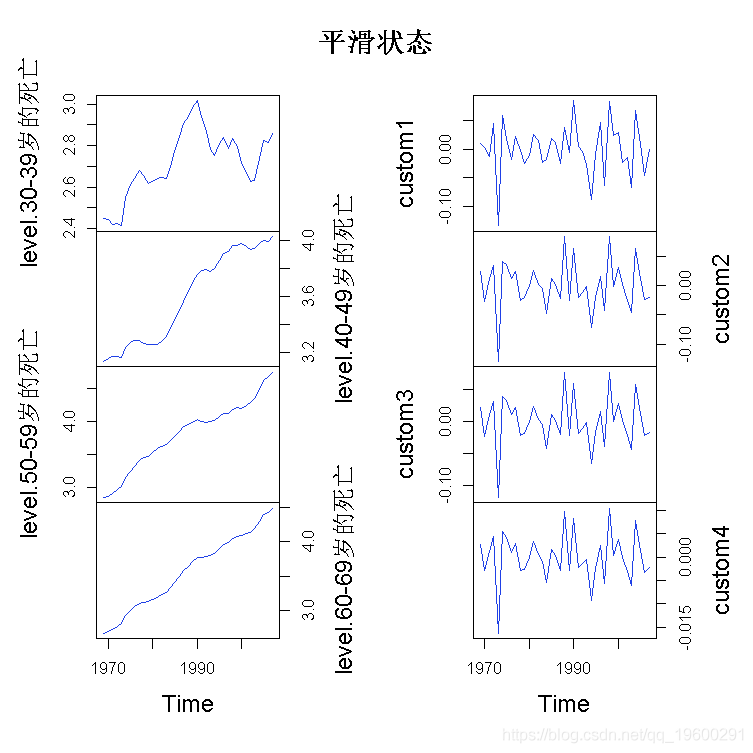
因此 , 要猜出好的初始值是很有挑战性的 , 特别是在更复杂的环境中 。 因此 , 在可以合理地确定找到适当的最优值之前 , 建议使用多种初始值配置 , 可能有几种不同类型的优化方法 。 这里我们使用观察到的系列的协方差矩阵作为协方差结构的初始值 。 在非高斯模型的情况下 , 另一个问题是 , 似然计算是基于迭代程序的 , 该程序使用一些终止条件(如对数似然的相对变化)停止 , 因此对数似然函数实际上包含一些噪声 。 这反过来又会影响BFGS等方法的梯度计算 , 在理论上可以得到不可靠的结果 。 因此 , 有时建议使用无导数的方法 , 如Nelder-Mead 。 另一方面 , BFGS通常比Nelder-Mead快得多 , 因此我更愿意先尝试BFGS , 至少在初步分析中 。 我们可以计算出状态的平滑估计 。
R> out <- KF(model,)
文章图片
【死亡|拓端数据tecdat:R语言:状态空间模型和卡尔曼滤波预测酒精死亡人数时间序列】我们看到残差之间偶尔有滞后的交叉相关 , 但总体上我们可以对我们的模型相对满意 。 现在我们可以用我们估计的模型预测2008-2013年每个年龄组与酒精有关的死亡强度e θt 。 由于我们的模型是时间变化的(u变化) , 我们需要通过newdata参数为未来的观察样本提供模型 。
- predict(model,
- + newdata +
- + interval = "confidence",)
文章图片
- for (i in 1:4) ts.plot(data[, i]/data[, 4 + i], trend[, i], pred[[i]]
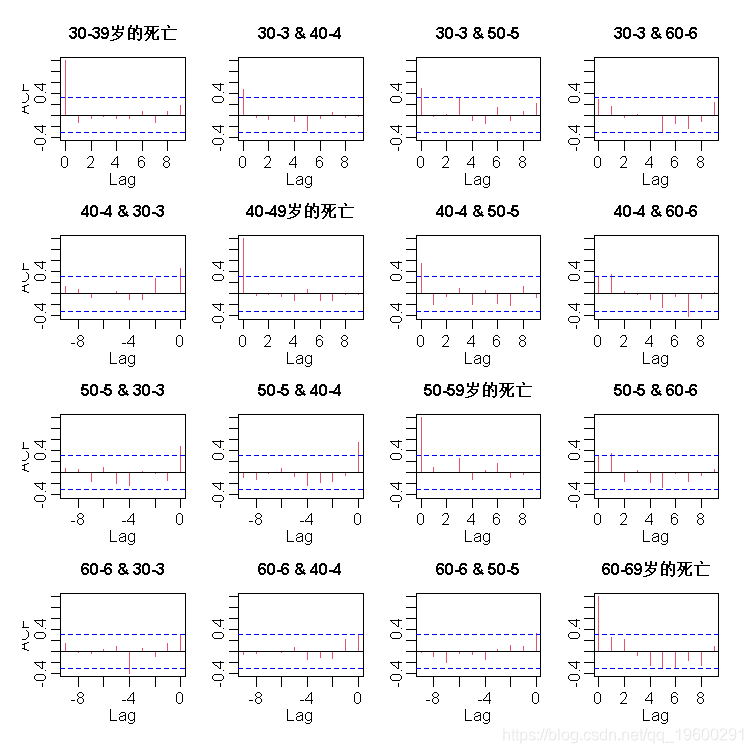
文章图片
图7显示了观察到的死亡人数 , 1969-2007年的平滑趋势 , 以及2008-2013年的预测 , 还有95%的预测区间 。 当我们将我们的预测与真实的观察结果进行比较时 , 我们看到在现实中 , 最年长的年龄组(60-69岁)的死亡人数略有增加 , 而在预测期间 , 另一个年龄组的死亡人数大幅下降 。 部分原因是在此期间酒精消费总量几乎单调下降 , 而这又可能是由于2008年、2009年和2012年酒精税的增加造成的 。
文章图片
讨论 状态空间模型提供了解决一大类统计问题的工具 。 在这里 , 我介绍了一个用于线性状态空间建模的方法 。

文章图片
最受欢迎的见解
1.在python中使用lstm和pytorch进行时间序列预测
2.python中利用长短期记忆模型lstm进行时间序列预测分析
3.使用r语言进行时间序列(arima , 指数平滑)分析
4.r语言多元copula-garch-模型时间序列预测
5.r语言copulas和金融时间序列案例
6.使用r语言随机波动模型sv处理时间序列中的随机波动
7.r语言时间序列tar阈值自回归模型
8.r语言k-shape时间序列聚类方法对股票价格时间序列聚类
9.python3用arima模型进行时间序列预测
推荐阅读






- 区块|面向2030:影响数据存储产业的十大应用(下):新兴应用
- 选型|数据架构选型必读:2021上半年数据库产品技术解析
- 殊荣|蝉联殊荣!数梦工场荣获DAMA2021数据治理三项大奖
- 数据|数智安防时代 东芝硬盘助力智慧安防新赛道
- IT|为什么感染飙升但死亡人数有限?研究显示T细胞可防止奥密克戎引发重症
- 德尔塔|为什么感染飙升但死亡人数有限?研究显示T细胞可防止奥密克戎引发重症
- 平台|数梦工场助力北京市中小企业公共服务平台用数据驱动业务创新
- 数据|中标 | 数梦工场以数字新动能助力科技优鄂
- 建设|数据赋能业务,数梦工场助力湖北省智慧应急“十四五”开局
- 市民|大数据、人工智能带来城市新变化 科技赋能深化文明成效