From: AI深度学习视线
目标检测技术的快速发展和广泛应用引起了对目标检测器的准确性和速度的关注 。 但是 , 当前的最新目标检测工作存在高延迟或者准确性不足的问 题 。
为了解决这一问题 , 作者及其团队提出了YOLObile框架 , 通过压缩编译协同设计在移动设备上进行实时目标检测 , 在三星S20上速度可达17FPS!比YOLOv4快5倍!同时mAP和FPS均优于YOLOv4-tiny!
一定要看到最后!文末有福利!

文章图片
一、摘要
目标检测技术的快速发展和广泛应用引起了对目标检测器的准确性和速度的关注 。 但是 , 当前的最新目标检测工作要么使用大型模型以准确性为导向 , 但导致高延迟 , 或者使用轻量级模型以速度为导向 , 但牺牲准确性 。
在这项工作中 , 研究团队提出了YOLObile框架 , 该框架是通过压缩编译协同设计在移动设备上进行实时目标检测的 。 针对任何内核大小 , 提出了一种新颖的block-punched剪枝方案 。 为了提高移动设备上的计算效率 , 采用了GPU-CPU协作方案以及高级的编译器辅助优化 。
实验结果表明 , 他们的剪枝方案以49.0 mAP达到YOLOv4压缩率的 14倍 。 在其YOLObile框架下 , 在Samsung Galaxy S20上使用GPU实现了17 FPS推理速度 。 通过合并其提出的GPU-CPU协作方案 , 推理速度提高到19.1 FPS , 并且比原始YOLOv4高出 5倍 。
二、本文思路
2.1 DNN Model Pruning
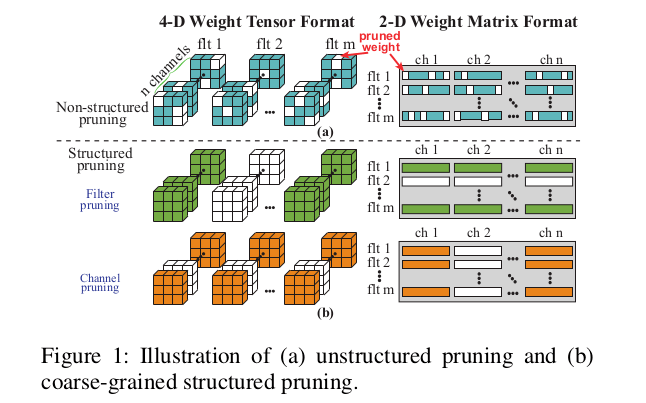
非结构化修剪允许对权值矩阵中任意位置的权值进行修剪 , 保证了搜索优化修剪结构的更高灵活性 , 如图1(a)所示 。 因此 , 通常压缩率高 , 精度损失小 。 但是 , 非结构化的剪枝会导致权值矩阵的不规则稀疏性 , 在计算过程中需要额外的索引来定位非零权值 。 这使得底层系统(例如 , 移动平台上的gpu)提供的硬件并行性得不到充分利用 。 因此 , 非结构化修剪不适用于DNN推理加速 , 甚至可以观察到速度的下降 。
文章图片
- 结构化剪枝
基于模式的剪枝被认为是一种细粒度结构的剪枝方案 。 由于其适当的结构灵活性和结构规律性 , 同时保持了精度和硬件性能 。 基于模式的剪枝包括核模式剪枝和连通性剪枝两部分 。 核模式修剪在每个卷积核中删除固定数量的权值 , 如图2所示 。

文章图片
2.2 Motivation
如上所述 , 最先进的目标检测工作要么是精度导向使用大模型大小或速度导向使用轻量级模型但牺牲精度 。 因此 , 它们都很难同时满足实际应用在移动设备上的准确性和延时要求 。
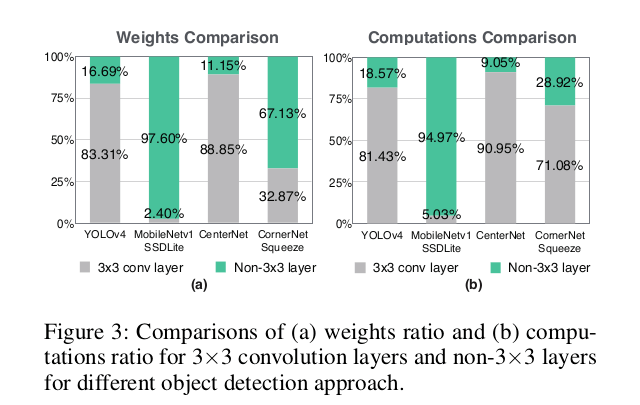
因此 , 我们需要 一种在移动设备上既能实现高精度又能实现低延迟的解决方案 。 而基于模式的修剪似乎是一个理想的选择 , 因为它在执行效率和准确性之间取得了平衡 。 但它只适用于3×3的CONV层 , 不利于目标检测任务的有效性 。 图3给出了3×3卷积层与非3×3层的对比 。 研究团队选择了 4种有代表性的目标检测方法 , 并比较了它们的权重和计算方法的百分比 。 例如 , 在YOLOv4中 , 一个代表最先进的目标检测网络 , 相当多的权重和计算量(分别为17%和19%)是由非3×3 CONV层贡献的 。
文章图片
编译器辅助的DNN推理加速是移动设备上低延迟DNN推理的另一个有吸引力的选择 。 实验证明 , 借助编译器优化 , 可以实现图像分类任务的低延迟DNN推理 。 然而 , 这样的加速仍然不足以满足目标检测任务所需的低延迟 , 因为它有大量的权重 , 需要更复杂的计算 。 为此 , 他们提出了两个关键的设计目标:
?目标1:我们需要一个剪枝方案 , 可以:
(i) 同时实现高精度和利用底层硬件并行性
(ii) 广泛应用于不同类型的层 。
?目标2:我们需要一种 更高效的计算方法来进一步加快目标检测任务的DNN推理速度 。
三、具体实现
3.1 Block-Punched Pruning
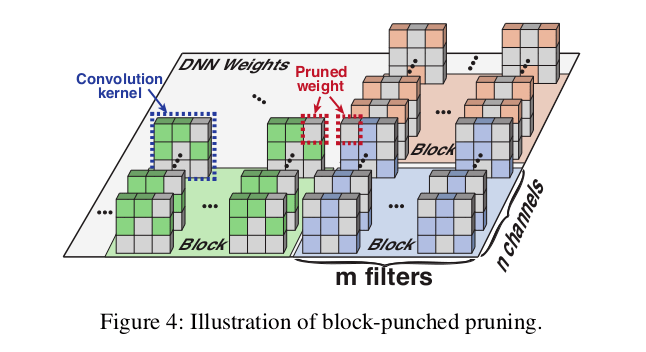
为了实现第3节中的第一个目标 , 研究团队提出了一种新的剪枝方案——block-punched剪枝 , 它在保持高精度的同时实现了高硬件并行性 。 除了3×3 CONV层外 , 还可以映射到其他类型的DNN层 , 如1×1 CONV层和FC层 。 尤其适用于资源有限的移动设备上的高效DNN推理 。 如图4所示 , 将某一层的整个DNN权值划分为若干等大小的块 , 每个块包含来自m个连续滤波器的n个连续信道的权值 。 在每个块中 , 他们 在所有过滤器的相同位置上修剪一组权值 , 同时在所有通道的相同位置上修剪权值 。 换句话说 , 被修剪的权重将穿透一个块内所有过滤器和通道的相同位置 。 请注意 , 每个块中经过修剪的权重的数量是灵活的 , 并且可以在不同的块之间有所不同 。
文章图片
从精度的角度来看 , 受基于模式的剪枝的启发 , 研究人员在block-punched剪枝中采用了一种细粒度的结构化剪枝策略 , 以增加结构的灵活性 , 减少精度的损失 。 从硬件性能的角度来看 , 与粗粒度结构修剪相比 , 他们的块打孔修剪方案通过利用适当的块大小和编译器级代码生成的帮助 , 能够实现高硬件并行性 。 原因是通常DNN层中的权重数非常大 。 即使将权重划分为块 , 每个块所需的计算量仍然足以饱和硬件计算资源 , 并实现高度并行 , 特别是在资源有限的移动设备上 。
此外 , 他们的修剪方案可以从内存和计算两个角度更好地利用硬件并行性 。 首先 , 在卷积计算中 , 所有的滤波器在每一层共享相同的输入 。 由于在每个块中的所有过滤器中删除了相同的位置 , 因此这些过滤器将跳过读取相同的输入数据 , 从而减轻处理这些过滤器的线程之间的内存压力 。 其次 , 限制在一个块内删除相同位置的通道 , 保证了所有这些通道共享相同的计算模式(索引) , 从而消除了处理每个块内通道的线程之间的计算发散 。
在他们的block-punched剪枝 , 块大小影响精度和硬件加速 。 一方面 , 更小的块大小提供了更高的结构灵活性 , 因为它的粒度更细 , 通常可以获得更高的精度 , 但代价是降低速度 。 另一方面 , 更大的块大小可以更好地利用硬件并行性来实现更高的加速度 , 但也可能造成更严重的精度损失 。
为了确定适当的块大小 , 研究团队 首先通过考虑设备的计算资源来确定每个块中包含的通道数 。 例如 , 他们为每个块使用与智能手机上移动CPU/GPU中的向量寄存器长度相同的通道数来实现高并行性 。 如果每个块中包含的信道数小于向量寄存器的长度 , 则向量寄存器和向量计算单元都将得不到充分利用 。 相反的 , 增加信道的数量并不会提高性能 , 反而会导致更严重的精度下降 。 因此 , 每个块中包含的滤波器的数量应该相应地确定 , 考虑到精度和硬件加速之间的权衡 。
通过推理速度可以推导出硬件加速度 , 不需要对DNN模型进行再训练就可以得到硬件加速度 , 与模型精度相比更容易推导 。 因此 , 设定合理的最小推理速度要求作为需要满足的设计目标 。 在块大小满足推理速度目标的情况下 , 他们选择在每个块中保留最小的滤波器数量 , 以减少精度损失 。
3.2 Reweighted Regularization Pruning Algorithm
在以前的权重修剪算法中 , 使用诸如组套索正则化或乘数交替方向方法(ADMM)被主要采用 。 但是 , 这会导致潜在的精度损失或需要手动压缩速率调整 。
因此 , 他们采用重新加权的方法 。 基本思想是系统地动态调整处罚 。 更具体地说 , 重加权方法减少了对较大量级的权重的惩罚(可能是更关键的权重) , 并增加了对较小量级的权重的惩罚 。
设W i∈R_M×N×K_h×K_w表示CNN的第i个CONV层的4-D权重张量 , 其中M是滤波器的数量;N是输入通道数;K_w和K_h是第i层的宽度和高度核心 。 一般的加权加权修剪问题表示为:
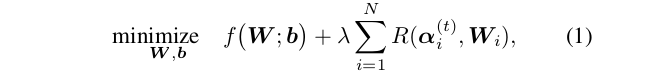
文章图片
在分块修剪中 , 每个W i分为K个块 , 因此 , 正则项为:
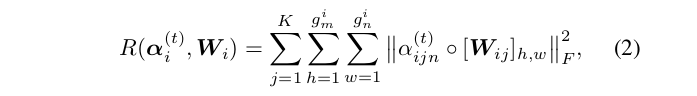
文章图片
修剪过程始于预训练的DNN模型 。 通过使用重新加权的正则化修剪算法进行另一个训练过程 , 可以获得具有他们的block-punched约束的修剪模型 。
3.3 Mobile Acceleration with a Mobile GPU-CPU Collaborative Scheme
在他们的框架中 , 研究团队结合了GPU-CPU协同计算方案来优化DNNs中的两种分支结构 , 即:
(1) 具有CONV层的分支结构
(2) 具有非CONV操作的分支结构 。
这两种分支结构的示例如图5 (a)和(b)所示 。 他们根据部署前的速度进行脱机设备选择 。

文章图片
我们知道 , GPU适合高并行性计算 , 比如卷积计算 , 在速度上明显优于CPU 。 因此 , 对于具有CONV层的分支结构 , 如YOLOv4中的Cross Stage Partial (CSP)块 , 如图5(a) , 选择GPU来计算最耗时的分支 , 剩下的问题是确定其他分支是使用CPU并发计算还是仍然使用GPU顺序计算 。
在图5(a)中 , 将分支1和分支2的GPU计算时间命名为t_g1、t_g2 , CPU计算时间命名为t_c1、t_c2 , 数据复制时间命名为他们在GPU中执行最耗时的分支1 , 然后对分支2进行决策 。 当使用CPU进行并行计算时 , 也可以需要添加数据复制时间 。 期望的GPU-CPU并行计算时间T_par取决于分支1和分支2的最大时间开销:
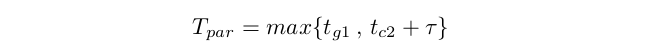
文章图片
仅gpu串行计算时间T_ser为两个支路计算时间T_g1 + T_g2的总和:
以YOLOv4中最终输出的三个YOLO头结构为例 , 如图5(b)所示 , 在每个分支中对最后一个CONV层的输出进行转置和重新排列后 , 我们仍然需要进行多次非CONV操作才能得到最终的输出 。 研究团队测量每个分支中非conv操作的GPU和CPU总执行时间 , 分别表示为t_g0, t_g1, t g2和t_c0, t_c1, t_c2 。 T_total表示所有三个分支的总计算时间 。
对于这三个分支 , 现在有8种可能的设备选择组合 。 例如 , 如果前两个分支使用CPU , 第三个分支使用GPU , 总的计算时间将是
请注意 , 最终输出迟早必须移至CPU , 因此不将数据复制时间计入总计算时间 。 结果 , 研究人员选择总计算时间最少的组合作为所需的计算方案 。 综上所述 , 他们提出的GPU-CPU协作方案可以有效提高硬件利用率并提高DNN推理速度 。
3.4 Compiler-assisted Acceleration
YOLObile依靠几种先进的编译器辅助优化 , 这些优化由研究团队新设计的块打孔修剪启用 , 以进一步提高推理性能 。 由于篇幅所限 , 在这里简要总结一下 。
首先 , YOLObile通过利用修剪信息来紧凑地存储模型权重 , 与众所周知的“压缩稀疏行”格式相比 , 修剪信息可以进一步压缩索引数组 。
其次 , YOLObile对块进行重新排序以提高内存和计算规则性 , 并消除不必要的内存访问 。
此外 , YOLObile采用高度并行的自动调整模型来查找最佳执行配置参数 。
YOLObile为每一层生成CPU和GPU代码 , 并在实际推理过程中根据他们的GPU-CPU协作方案调用正确的代码 。
四、代码实操
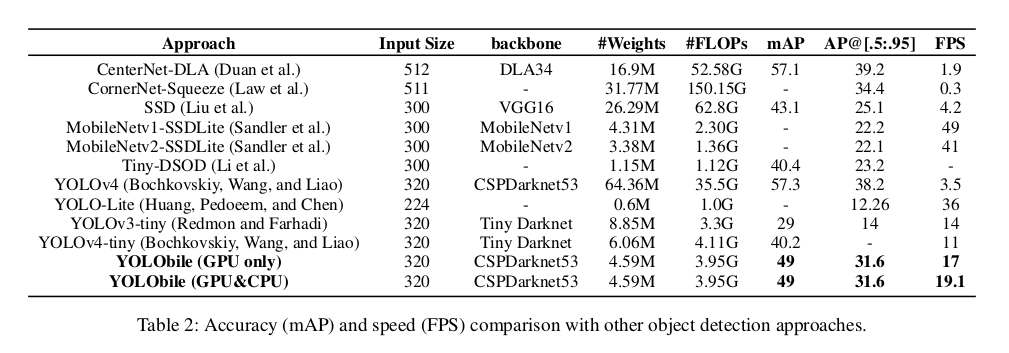
4.1 Ablation Study

文章图片
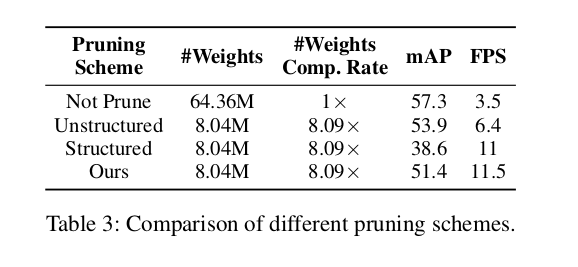
文章图片
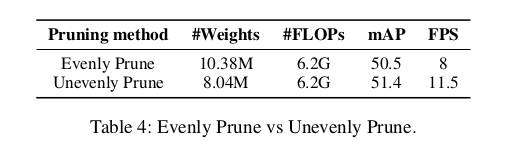
文章图片
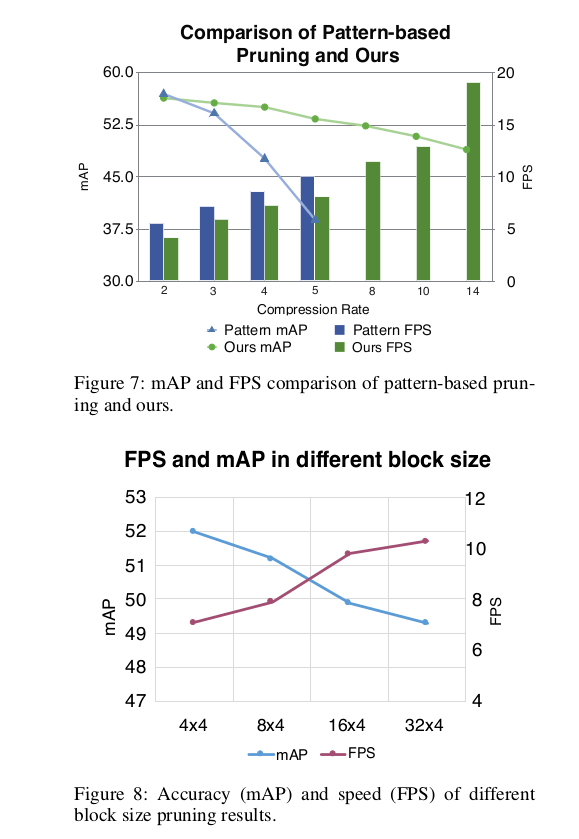
文章图片
4.2 Evaluation of YOLObile framework
【YOLObile|超越YOLOv4-tiny!YOLObile:移动设备上的实时目标检测】
文章图片
推荐阅读




- 手机|1千亿让小米超越苹果?别被雷军的障眼法,忽悠了
- 苹果|小米12系列手机发布,雷军:要在未来一步步超越苹果
- 雷军|小米史上最强、最小、最薄手机!3699起售…雷军:超越苹果
- 超越|小米12正式发布!雷布斯首次对标苹果,售价3699元起
- 赵明|【品牌】荣耀X30开售 | 赵明放话MagicV超越市面上所有折叠屏
- 榜首|最新!TikTok超越谷歌,成2021年全球访问量最大的互联网网站
- 超越|超越传统容灾英方云匠心筑创新云之路
- 超越|荣耀60系列全能实力溢出:续航超越友商5000mAh机型
- 国人|杨振宁的物理成就已经超越爱因斯坦?
- 团队|14 公里全球最远,浙大自主研发水声通信机实现技术超越